
Introdução
Os proxies são principalmente usados para permitir acesso à
Web através de um firewall (Figura 1). Um proxy é um servidor
HTTP especial que tipicamente roda em uma máquina firewall. O proxy
espera por uma requisição dentro do firewall, a repassa para
o servidor remoto do outro lado do firewall, lê a resposta e envia
de volta ao cliente.
O proxy roda ou em um servidor firewall ou qualquer outro servidor interno que tenha acesso total a Internet - ou em uma máquina dentro do firewall, fazendo conexões com o mundo exterior através de SOCKS ou qualquer outro software firewall.
Normalmente, o mesmo proxy é usado por todos os clientes em uma subrede. Isto torna possível para ele fazer caching eficiente de todos os documentos requisitados.
A habilidade que o proxy tem no uso do cache, o torna atrativo para
aqueles que não estão dentro do firewall. Configurar um servidor
proxy é fácil e os mais populares programas clientes Web
já tem suporte a essa ferramenta. Sendo assim, torna-se simples
a tarefa de configurar um grupo de trabalho inteiro para usar o serviço
de cache do proxy. Isto reduz os custos com tráfego de rede porque
muitos documentos que são requisitados são lidos do cache
local.
Por que um nível de aplicação
proxy?
Um nível de aplicação proxy faz um firewall seguramente permeável para os usuários na organização, sem criar um furo na segurança onde hackers poderiam entrar na rede da organização.
Para clientes Web, as modificações necessárias para suportar um nível de aplicação proxy são menores (leva-se apenas 5 minutos para adicionar suporte proxy para o Emacs Web Browser).
Não há necessidade de compilar versões especiais
de clientes Web com bibliotecas firewall. Em outras palavras, quando se
usa proxy não é necessário customizar cada cliente
para suportar um tipo ou método especial de firewall:
o proxy, em si, é um método padrão para acessar
firewalls.
Os usuários não têm que ter clientes FTP, Gopher e WAIS separados (muito menos modificados) para acessar um firewall - um simples cliente Web com um servidor proxy trata todos esse casos.
O proxy permite que os programadores esqueçam as dezenas de milhares
de linhas de código necessárias para suportar cada protocolo
e se concentrem em coisas mais importantes - é possível ter
clientes que somente compreendam HTTP (nenhum suporte nativo aos protocolos
FTP, Gopher, etc). Usando HTTP entre o cliente e o proxy, nenhuma funcionalidade
é perdida, pois FTP, Gopher e outros protocolos Web são bem
mapeados para o HTTP.
Detalhes Técnicos
Quando uma requisição HTTP normal é feita por um cliente, o servidor pega somente o path e a "porção chave" da URL requisitada (Figura 2); outras partes, como o especificador de protocolo "http:" e o nome do servidor são obviamente claros para o servidor HTTP remoto. O path requisitado especifica um documento ou um script CGI no sistema de arquivos local do servidor; ou ainda algum outro recurso disponível daquele servidor.
Quando um usuário entra:
http://mycompany.com/information/ProxyDetails.html
O browser converte para:
GET /information/ProxyDetails.html
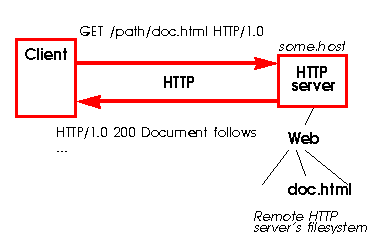
O cliente faz a requisição ao servidor HTTP especificando
apenas o recurso relativo àquele servidor (nenhum protocolo ou nome
de servidor é colocado na URL).
Cliente
Muitos clientes WWW são construídos no topo de libwww,
a WWW Common Library, que trabalha com os diferentes protocolos
de comunicação usados na Web: HTTP, FTP, Gopher, News e WAIS.
O suporte do proxy é feito automaticamente por clientes usando a libwww. Variáveis de ambiente são usadas para controlar a biblioteca. Existe uma variável de ambiente individual para cada protocolo de acesso, por exemplo: http_proxy, ftp_proxy, gopher_proxy e wais_proxy. Essas variáveis são configuradas para apontar para o proxy que deve servir às requisições desse protocolo, por exemplo:
ftp_proxy=http://www_proxy.domain:911/
export ftp_proxy
Normalmente um único servidor proxy trata todos os protocolos, mas não é necessário que seja assim.
Quando a variável de ambiente para um certo protocolo é definida, o código libwww faz com que a conexão sempre seja feita para o proxy e não diretamente com o servidor remoto.
A última versão de libwww suporta as chamadas "lista de exceções", que são localizações que devem ser atingidas sem o auxílio do proxy. Isso é extremamente útil quando o acesso trata-se de servidores locais, onde o acesso pode ser feito sem nenhum proxy.
Outra diferença no protocolo é que a URL requisitada pelo cliente deve ser completa se for uma operação com o proxy. Essas são as únicas diferenças entre uma transação HTTP normal e uma com proxy. A simplicidade do suporte proxy faz com que mesmo clientes não baseados em libwww possam facilmente suportá-lo.
O suporte proxy é implementado somente para HTTP/1.0 no lado
do servidor: todos os clientes devem usar esse protocolo. Isto não
é um problema porque libwww faz isto automaticamente e a maioria
dos clientes (se não todos) já
têm sido atualizados para HTTP/1.0.
Servidor
O proxy deve ser capaz de agir tanto como um servidor como um cliente.
Ele age como um servidor quando aceita requisições HTTP de
clientes conectados a ele e age como cliente quando se conecta com servidores
remotos para
conseguir retornar (ou atualizar) os documentos para seus clientes.
Os campos do cabeçalho passados para o proxy pelo cliente são
usados sem modificações quando o proxy se conecta ao servidor
remoto, de forma que o cliente não
perde qualquer funcionalidade quando existe um proxy como intermediário.
Um proxy "completo" deveria falar todos os protocolos Web (os mais importantes
são HTTP, FTP, Gopher, WAIS e NTTP). Proxies que somente lidam com
um único protocolo Internet, como o HTTP, também são
uma possibilidade, mas um cliente Web deveria então requerer acesso
a outro proxy quando quisesse usar outro protocolo (para isso que existem
as variáveis de ambiente).
Cache
A idéia básica no cache é simples: armazenar os
documentos retornados em um arquivo local para uso posterior de forma que
não seja necessário se conectar ao servidor remoto na próxima
vez que o documento for requisitado (Figuras 3 e 4).
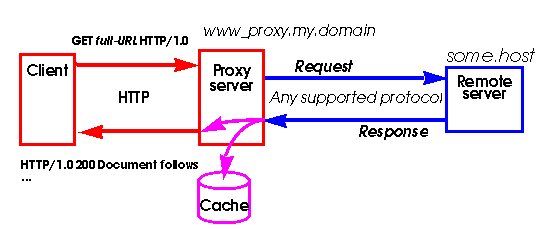
O documento requisitado é pego do servidor remoto e armazenado
localmente para uso futuro.
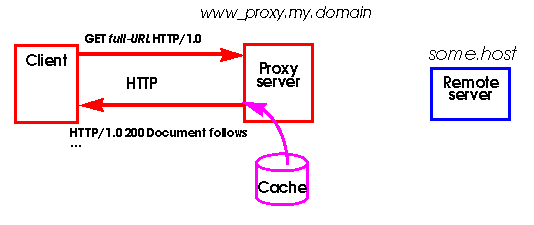
Se uma versão atualizada do documento é encontrada no
cache do proxy nenhuma conexão ao servidor remoto é necessária.
Inclusões no protocolo
Quando é essencial que o documento retornado esteja atualizado,
é necessário contactar o servidor remoto para cada requisição
GET. O protocolo HTTP já contém o método HEAD para
retornar a informação do cabeçalho de um
documento, mas não o documento em si. Isto é útil
para checar se o documento foi modificado desde o último acesso.
O protocolo HTTP foi modificado para conter uma requisição do tipo If-Modified-Since que torna possível fazer uma requisição GET condicional. Esta é essencialmente a mesma requisição GET exceto pelo cabeçalho que contém a data e a hora que o objeto está armazenado no cliente (no nosso caso, no cache do proxy).
Se o documento não foi modificado desde a data e a hora especificada ele não será retornado. O cliente receberá como resposta apenas informações relevantes. Se, caso contrário, o documento foi modificado, ele será retornado como se a requisição fosse um GET normal.
Se o servidor HTTP remoto não suportar o GET condicional nenhum erro será retornado: ele simplesmente retornará todo o arquivo como se a requisição se tratasse de um GET comum. Felizmente todos os grandes servidores HTTP já suportam o GET condicional.
O mecanismo de cache é baseado em disco, o que significa que
o boot do proxy ou da própria máquina nada lhe afetará.
Devido a este detalhe, o cache abre novas possibilidades quando o proxy
e um cliente Web estão na mesma máquina. O proxy pode ser
configurado para usar somente o cache local, possibilitando a realização
de demonstrativos sem uma conexão internet. Você pode até
desplugar um notebook e levá-lo ao bar.
Ligação entre Proxies
O encadeamento de proxies deixa você usar um proxy como um cache local de um departamento de uma grande organização. Esses departamentos têm controle sobre o servidor e o cache. Esse servidor proxy departamental pode conectar-se a um proxy firewall entre a Internet e a organização. Esse servidor proxy fala com a Internet como mostrado na Figura 5.
Qualquer restrição de acesso do proxy mais externo tem precedência sobre o mais interno (departamental).
Por exemplo, imagine que o proxy departamental 1 está configurado
para aceitar qualquer URL e o proxy da organização (organizacional)
está configurado para impedir que URLs da França sejam aceitas.
Desta forma, uma
requisição do proxy departamental 1 pode ser negado pelo
proxy organizacional.
