| Conceito: Mecanismos de Design e Implementação |
 |
|
| Elementos Relacionados |
|---|
Introdução aos Mecanismos de Design e ImplementaçãoUm mecanismo de design é um aperfeiçoamento de um mecanismo de análise correspondente (consulte também o Conceito: Mecanismos de Análise). Um mecanismo de design acrescenta detalhes concretos ao mecanismo de análise conceitual, mas quase não exige tecnologia específica. Suponhamos, por exemplo, a implementação de um sistema de gerenciamento de banco de dados orientado a objetos feita por um fornecedor específico. Como nos mecanismos de análise, um mecanismo de design pode instanciar um ou mais padrões, neste caso, padrões arquiteturais o de design. Da mesma forma, um mecanismo de implementação é um refinamento de um mecanismo de design correspondente, utilizando, por exemplo, uma linguagem de programação específica e outra tecnologia de implementação (como um produto de middleware do fornecedor específico). Um mecanismo de implementação pode instanciar um ou mais idiomas ou padrões de implementação. Exemplo: Características de Mecanismos de DesignConsidere o mecanismo de análise para Persistência:
Esses objetos exigirão um suporte diferente para a persistência; as seguintes características dos mecanismos de design para suporte de persistência podem ser identificadas:
Observe que essas velocidades são somente classificadas como 'lentas' em relação ao armazenamento na memória. Obviamente, em alguns ambientes, a utilização do armazenamento em cache pode aprimorar os tempos de acesso aparentes. Refinando o Mapeamento entre os Mecanismos de Design e ImplementaçãoInicialmente, o mapeamento entre os mecanismos de design e os mecanismos de implementação provavelmente não será ideal, mas manterá o projeto em execução, identificará os riscos ainda não observados e disparará posteriormente investigações e avaliações. À medida que o projeto continuar e ganhar mais conhecimento, o mapeamento precisará ser refinado. Proceda iterativamente para refinar o mapeamento entre os mecanismos de design e de implementação, eliminar caminhos redundantes, trabalhando "de cima para baixo" e "de baixo para cima". Trabalhando de Cima para Baixo. Ao trabalhar "de cima para baixo", novas e refinadas realizações de caso de uso colocarão novos requisitos nos mecanismos de design necessários por meio dos mecanismos de análise necessários. Esses novos requisitos podem revelar características adicionais de um mecanismo de design, forçando uma divisão entre os mecanismos. Existe também um comprometimento entre a complexidade do sistema e seu desempenho:
Trabalhando de Baixo para Cima. Ao trabalhar "de baixo para cima", investigando os mecanismos de implementação disponíveis, você pode encontrar produtos que satisfazem vários mecanismos de design de uma vez, mas forçam alguma adaptação e reparticionamento dos seus mecanismos de design. Você quer minimizar o número de mecanismos de implementação utilizados, mas ter uma pequena quantidade de mecanismos pode gerar problemas de desempenho. Depois que você decidir usar um DBMS para armazenar objetos de classe A, provavelmente se verá tentado a utilizá-lo para armazenar todos os objetos do sistema. Essa prática pode se revelar bastante ineficaz ou bastante inconveniente. Nem todos os objetos que exigem persistência precisam ser armazenados no DBMS. Alguns objetos podem ser persistentes, mas podem ser freqüentemente acessados pelo aplicativo e raramente acessados por outros aplicativos. Adotar uma estratégia híbrida em que o objeto seja lido do DBMS para a memória e periodicamente sincronizado pode ser a melhor abordagem. Exemplo Um vôo pode ser armazenado na memória para fins de acesso rápido e em um DBMS para fins de persistência a longo prazo. No entanto, isso disparará a necessidade de um mecanismo sincronizar ambos. É comum ter mais de um mecanismo de design associado a uma classe cliente como indício de um comprometimento entre as diferentes características. Como os mecanismos de implementação são geralmente fornecidos em pacotes de componentes (sistemas operacionais e produtos personalizados) desenvolvidos internamente e adquiridos prontos para serem usados, será necessária uma certa otimização baseada no custo, uma desproporção de impedância ou uma uniformidade de estilo. Além disso, os mecanismos são geralmente interdependentes, o que dificulta a separação clara dos serviços em mecanismos de design. Exemplos
O refinamento continua no decorrer de toda a fase de elaboração e representa sempre um comprometimento entre:
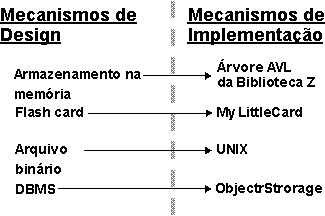
A meta geral é sempre ter um conjunto simples de mecanismos que proporcionem a um sistema grande integridade conceitual, simplicidade e elegância. Exemplo: Mapeando Mecanismos de Design para Mecanismos de ImplementaçãoOs mecanismos de design de Persistência podem ser mapeados para os mecanismos de implementação da seguinte maneira:
Um possível mapeamento entre os mecanismos de análise e os mecanismos de design. As setas pontilhadas significam "é especializado por", afirmando que as características dos mecanismos de design são herdadas dos mecanismos de análise, mas serão especializadas e refinadas. Depois que você tiver terminado de otimizar os mecanismos, estes serão os mapeamentos resultantes:
O mapa deve ser navegável em ambas as direções, para que seja fácil determinar as classes cliente quando os mecanismos de implementação forem alterados. Descrevendo Mecanismos de DesignOs mecanismos de design e os detalhes relacionados ao seu uso são documentados no Produto de Trabalho: Diretrizes Específicas do Projeto. O relacionamento (ou mapeamento) de mecanismos de análise com os mecanismos de design, os mecanismos de implementação e a análise racional associada a essas opções é documentado no Produto de Trabalho: Documento de Arquitetura de Software. Como nos mecanismos de análise, os mecanismos de design podem ser modelados utilizando uma colaboração, que pode instanciar um ou mais padrões de arquiteturaou design. Exemplo: Um Mecanismo de PersistênciaEste exemplo utiliza uma instância de um padrão de persistência com base em RDBMS retirado da JDBC™ (Java Data Base Connectivity). Embora o design seja apresentado aqui, a JDBC fornece o verdadeiro código para algumas das classes, portanto, é um pequeno passo a partir do que é apresentado aqui para um mecanismo de implementação. A Visualização Estática da figura: a JDBC mostra as classes (estritamente, as funções do classificador) na colaboração.
Visualização Estática: JDBC As classes preenchidas com amarelo são as que foram fornecidas, as outras (myDBClass etc.) foram ligadas pelo designer para criar o mecanismo. Na JDBC, um cliente trabalhará com uma DBClass para ler e gravar dados persistentes. A DBClass é responsável por acessar o banco de dados JDBC utilizando a classe DriverManager. Assim que um banco de dados Connection é aberto, a DBClass pode criar instruções SQL que serão enviadas para o RDBMS de suporte e executadas utilizando a classe Statement. A classe Statement é a que "fala" com o banco de dados. O resultado da consulta SQL é retornado em um objeto ResultSet. A classe DBClass é responsável por tornar outra instância da classe persistente. Ela compreende o mapeamento OO-para-RDBMS e faz a interface com o RDBMS. A DBClass serializa o objeto, grava-o no RDBMS e lê os dados do objeto a partir do RDBMS e constrói o objeto. Cada classe que seja persistente terá uma DBClass correspondente. A PersistentClassList é utilizada para retornar um conjunto de objetos persistentes como um resultado de uma consulta do banco de dados (por exemplo, DBClass.read()). Agora, apresentaremos uma série de visões dinâmicas, a fim de mostrar como o mecanismo realmente funciona.
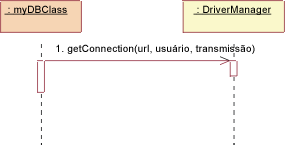
JDBC: Inicializar A inicialização deve ocorrer antes que qualquer classe persistente possa ser acessada. Para inicializar a conexão com o banco de dados, a DBClass deve carregar o driver apropriado chamando a operação getConnection() da classe DriverManager com um URL, um usuário e uma senha. A operação getConnection() tenta estabelecer uma conexão com a URL do banco de dados fornecido. O DriverManager tenta selecionar um driver apropriado a partir do conjunto de drivers JDBC registrados. Parâmetros: url: Uma url do banco de dados da jdbc:subprotocol:subname. Essa URL é utilizada para localizar o verdadeiro servidor do banco de dados e não está relacionada à Web nesta instância. user: O usuário do banco de dados em cujo nome a Conexão está sendo feita pass: A senha do usuário Retorna: uma conexão com o URL.
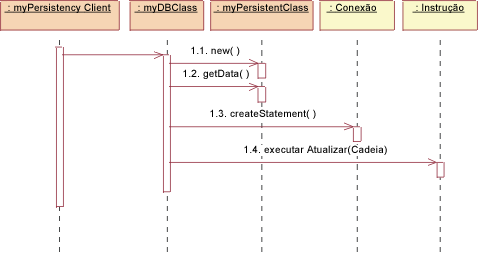
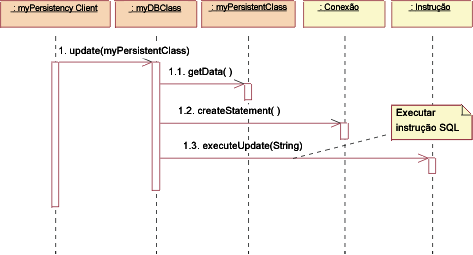
JDBC: Criar Para criar uma nova classe, o cliente da persistência pede à DBClass para criar a nova classe. A DBClass cria uma nova instância de PersistentClass com valores padrão. Em seguida, ela cria uma nova instrução usando a operação createStatement() da classe Connection. A Statement é executada e os dados são inseridos no banco de dados.
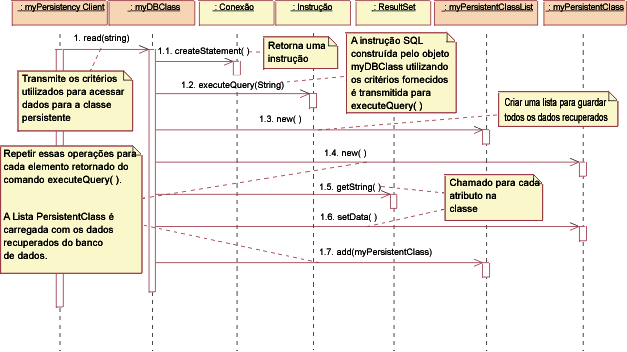
JDBC: Ler Para ler uma classe persistente, o cliente da persistência pede à DBClass para ler. A DBClass cria uma nova instrução usando a operação createStatement() da classe Connection. A instrução é executada e os dados são retornados em um objeto ResultSet. Em seguida, a DBClass cria uma nova instância da PersistentClass e a preenche com os dados recuperados. Os dados são retornados em um objeto de coleta, uma instância da classe PersistentClassList. Nota: A cadeia transmitida para executeQuery() não é necessariamente exatamente a mesma cadeia transmitida para read(). A DBClass criará a consulta SQL para recuperar os dados persistentes do banco de dados, usando os critérios passados para read(). Isso acontece porque não queremos que o cliente da DBClass precise do conhecimento dos internos do banco de dados para criar uma consulta válida. Este conhecimento é encapsulado dentro da DBClass.
JDBC: Atualizar Para atualizar uma classe, o cliente da persistência pede à DBClass para atualizar. A DBClass recupera os dados do objeto PersistentClass fornecido e cria uma nova instrução usando a operação createStatement() da classe Connection. Assim que a Statement for construída, a atualização será executada e o banco de dados será atualizado com os novos dados da classe. Lembre-se: É tarefa da DBClass "serializar" a PersistentClass e gravá-la no banco de dados. É por isso que deve ser recuperada da PersistentClass específica antes de criar a Instrução SQL. Nota: No mecanismo acima, a PersistentClass deve fornecer rotinas de acesso para todos os dados persistentes para que a DBClass possa acessá-los. Isso permite o acesso externo a determinados atributos persistentes que, do contrário, teriam sido privados. Este é um preço que você tem que pagar para arrancar o conhecimento de persistência da classe que encapsula os dados.
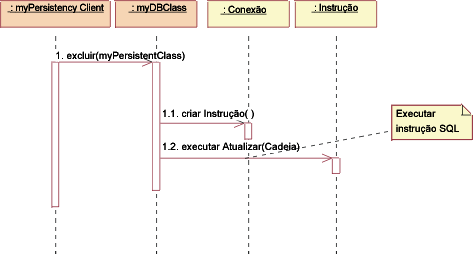
JDBC: Excluir Para excluir uma classe, o cliente da persistência pede à DBClass para excluir a PersistentClass. A DBClass cria uma nova instrução usando a operação createStatement() da classe Connection. A Statement é executada e os dados são removidos do banco de dados. Na implementação deste design, algumas de decisões seriam tomadas sobre o mapeamento da DBClass para as classes persistentes, por exemplo, ter uma DBClass por classe persistente e alocá-las para os pacotes apropriados. Esses pacotes terão uma dependência no java.sql fornecido (consulte o pacote JDBC™ API Documentation), o qual contém as classes de suporte DriverManager, Connection, Statement e ResultSet. |



© Copyright IBM Corp. 1987, 2006. Todos os Direitos Reservados. |