| Conceito: Padrões de Distribuição |
 |
|
| Elementos Relacionados |
|---|
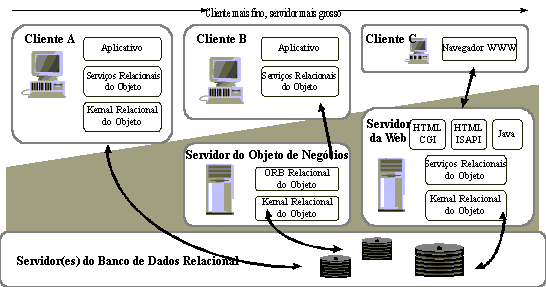
Nós, Processadores e DispositivosOs Processadores e Dispositivos são estereótipos comuns do Nó. A distinção entre os dois pode parecer difícil de avaliar, já que muitos dispositivos agora contêm suas próprias CPUs. No entanto, a distinção entre processadores e dispositivos está no tipo de software que os executa. Os processadores executam programas/softwares que foram explicitamente escritos para o sistema que está sendo desenvolvido. Eles são dispositivos de computação para fins gerais, que apresentam capacidade de computação, memória e capacidade de execução. Os dispositivos executam o software escrito que controla a funcionalidade do próprio dispositivo. Em geral, eles são conectados a um processador que controla o dispositivo, executam o software incorporado e são incapazes de executar programas para fins gerais. Sua funcionalidade é geralmente controlada pelo software do driver de dispositivo. Padrões de DistribuiçãoExiste uma série de padrões de distribuição comuns nos sistemas, dependendo da funcionalidade do sistema e do tipo de aplicativo. Em muitos casos, o padrão de distribuição é informalmente usado para descrever a 'arquitetura' do sistema, embora a arquitetura completa abranja isso, mas também muitos outros elementos. Por exemplo, muitas vezes, um sistema será descrito como detentor de uma 'arquitetura cliente-servidor', embora isso seja somente o aspecto de distribuição da arquitetura. Isso serve para destacar a importância dos aspectos de distribuição do sistema e até que ponto eles influenciam outras decisões de arquitetura. Os padrões de distribuição descritos a seguir implicam determinadas características de sistema, características de desempenho e arquiteturas de processo. Cada um deles soluciona determinados problemas, mas também propõe desafios exclusivos. Arquiteturas de Cliente/ServidorEm "arquiteturas de cliente/servidor", há nós de processador de rede especializados denominados clientes e nós denominados servidores. Os clientes são consumidores dos serviços fornecidos por um servidor. Geralmente, um cliente atende a um único usuário e resolve os serviços de apresentação de usuário final (GUIs), enquanto o servidor fornece serviços aos diversos clientes simultaneamente. Os serviços fornecidos são, em geral, serviços de banco de dados, de segurança ou de impressão. Nesses sistemas, a "lógica do aplicativo" ou lógica de negócios é normalmente distribuída entre o cliente e o servidor. A distribuição da lógica de negócios é denominada particionamento do aplicativo. Na figura a seguir, o Cliente A mostra um exemplo de arquitetura em 2 camadas, com a maioria da lógica do aplicativo localizada no servidor. O Cliente B mostra uma arquitetura em 3 camadas comum, com os Serviços de Negócios implementados em um Servidor de Objeto de Negócios. O Cliente C mostra um aplicativo comum baseado na Web.
Variações de Arquiteturas Cliente-Servidor Nos sistemas cliente/servidor tradicionais, a maior parte da lógica de negócios é implementada nos clientes, mas alguns recursos ficam melhor alocados no servidor como, por exemplo, a funcionalidade que geralmente acessa os dados armazenados no servidor. Fazendo isso, uma pessoa pode reduzir o tráfego da rede, o que, na maioria dos casos, é muito caro (é uma ordem de grandeza ou duas mais lento do que a comunicação entre processos). Algumas características:
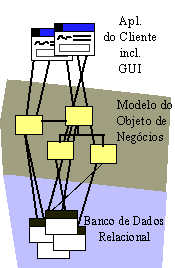
A 'Arquitetura em 3 Camadas'A 'Arquitetura em 3 Camadas' é um caso especial da 'Arquitetura de Cliente/Servidor' em que a funcionalidade no sistema é dividida em 3 partições lógicas: serviços de aplicativo, serviços de negócios e serviços de dados. As 'partições lógicas' podem, na verdade, ser mapeadas para três ou mais nós físicos.
Exemplo de uma Arquitetura em 3 Camadas O particionamento lógico nessas três 'camadas' reflete uma observação sobre como a funcionalidade em aplicativos típicos de escritório tende a ser implementada e como ela é alterada. Os serviços de aplicativo, que lidam basicamente com as questões de apresentação da GUI, tendem a ser executados em uma estação de trabalho de desktop dedicada com um ambiente operacional gráfico de janelas. As alterações na funcionalidade tendem a ser impostas pela facilidade de uso ou por considerações estéticas, essencialmente por fatores humanos. Os serviços de dados tendem a ser implementados por meio de uma tecnologia de servidor de banco de dados, que, por sua vez, tende a ser executada em um ou mais nós de alto desempenho e alta largura de banda que atendem a centenas ou milhares de usuários conectados a uma rede. É bem provável que os serviços de dados sejam alterados quando a representação e os relacionamentos entre as informações armazenadas também forem alterados. Os serviços de negócios refletem o conhecimento codificado dos processos de negócios. Eles manipulam e sintetizam as informações obtidas nos serviços de dados e as fornecem aos serviços de aplicativo. Os serviços de negócios são geralmente usados por vários usuários em comum e, portanto, eles tendem a ser alocados em servidores especializados também, embora possam residir nos mesmos nós que os serviços de dados. A funcionalidade de particionamento ao longo dessas linhas fornece um padrão relativamente confiável para fins de escalabilidade: incluindo servidores e equilibrando novamente o processamento entre os servidores de dados e de negócios, um grau maior de escalabilidade é alcançado. A 'Arquitetura Fat Client'O cliente é Fat porque quase tudo é executado nele (exceto em uma variação denominada 'arquitetura em 2 camadas', em que os serviços de dados são alocados em um nó separado). Os Serviços de Aplicativo, Serviços de Negócios e Serviços de Dados residem na máquina cliente. O servidor de banco de dados fica geralmente em outra máquina.
Arquitetura tradicional em 2 camadas ou "Fat Client" Os 'Fat Clients' são relativamente simples de projetar e construir. No entanto, eles são mais difíceis de distribuir (pois tendem a ser grandes e monolíticos) e manter. Como as máquinas cliente tendem a armazenar os dados em cache localmente para fins de desempenho, a coerência e consistência do cache local tendem a ser questões e áreas que garantem atenção particular. As mudanças efetuadas nos objetos armazenados em vários caches locais são difíceis e caras de coordenar, envolvendo transmissões das mudanças em rede. A 'Arquitetura Fat Server'Na outra extremidade do espectro da arquitetura 'Fat Client' está a arquitetura 'Fat Server' ou 'Anorexic Client'. Um exemplo típico é o aplicativo de navegador da Web executando um conjunto de páginas HTML, em que há pouquíssimos aplicativos no cliente. Quase todo o trabalho é realizado em um ou mais servidores da Web e servidores de dados.
Aplicativo da Web Os aplicativos da Web são fáceis de distribuir e de alterar. Eles são relativamente baratos de desenvolver e suportar (já que grande parte da infra-estrutura do aplicativo é fornecida pelo navegador e pelo servidor da Web). Eles podem, no entanto, não fornecer o grau desejado de controle no aplicativo e tendem a saturar a rede rapidamente se não forem bem projetados (e, algumas vezes, apesar de serem bem projetados). Arquitetura de Cliente/Servidor DistribuídoNesta arquitetura, os serviços de aplicativo, de negócios e de dados residem em diferentes nós, possivelmente com especialização de servidores nas camadas de serviços de negócios e de serviços de dados. Uma realização completa de uma arquitetura em 3 camadas. A Arquitetura de Ponto a PontoNa arquitetura ponto a ponto, qualquer processo ou nó do sistema pode ser cliente e servidor. A distribuição da funcionalidade é obtida por meio do agrupamento de serviços inter-relacionados, a fim de minimizar o tráfego da rede e, ao mesmo tempo, maximizar a taxa de transferência e a utilização do sistema. Esses sistemas tendem a ser complexos e há uma maior necessidade de conhecer as questões como dead-lock, escassez entre processos e tratamento de falhas. |


© Copyright IBM Corp. 1987, 2006. Todos os Direitos Reservados. |