| Conceito: Orientação a Objetos e Bancos de Dados Relacionais |
 |
|
| Elementos Relacionados |
|---|
IntroduçãoEste documento de conceito fornece uma visão geral de modelos de objetos e modelos de dados relacionais e também uma descrição resumida de uma estrutura de persistência. Orientação a Objetos e Bancos de Dados RelacionaisA orientação a objetos e os bancos de dados relacionais não são totalmente compatíveis. Eles representam duas visualizações diferentes: em um RDBMS, tudo o que você vê são os dados; em um sistema Orientado a Objetos, tudo o que você vê é o comportamento. Não é que uma perspectiva seja melhor que a outra: o modelo Orientado a Objetos tende a funcionar melhor em sistemas com comportamento complexo e específico de estados, nos quais os dados são secundários, ou em sistemas nos quais os dados são acessados, através de navegação, em uma hierarquia natural (por exemplo, listas de materiais). O modelo RDBMS é adequado para relatar aplicativos e sistemas cujos relacionamentos sejam dinâmicos ou ad-hoc. A verdade é que um volume grande de informações é armazenado em bancos de dados relacionais e, se os aplicativos orientados a objetos quiserem ter acesso a esses dados, precisam ser capazes de ler e gravar em um RDBMS. Além disso, é comum os sistemas orientados a objetos precisarem compartilhar dados com sistemas que não são orientados a objetos. É natural, portanto, usar um RDBMS como mecanismo de compartilhamento. Embora o design orientado a objetos e o design relacional compartilhem algumas características em comum (os atributos de objeto são teoricamente semelhantes às colunas de entidades), há diferenças fundamentais que fazem da integração completa um desafio. A diferença básica é que os modelos de dados expõem os dados (através de valores de coluna), enquanto os modelos de objeto ocultam os dados (encapsulados atrás de suas interfaces públicas). O Modelo de Dados RelacionalO modelo relacional é composto de entidades e relacionamentos. Uma entidade pode ser uma tabela física ou uma projeção lógica de diversas tabelas, também conhecida como visão. A figura a seguir ilustra as tabelas LINEITEM, ORDER e PRODUCT e os vários relacionamentos entre elas. Um modelo relacional tem os seguintes elementos:
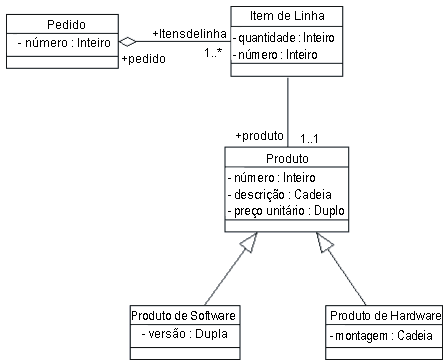
Um Modelo Relacional As entidades têm colunas. Cada coluna é identificada por um nome e um tipo. Na figura acima, a entidade LINEITEM contém as colunas LineItem_Id (a chave primária), Description, Price, Quantity, Product_Id e Order_Id (as duas últimas são chaves estrangeiras que vinculam a entidade LINEITEM às entidades ORDER e PRODUCT). As entidades têm registros ou linhas. Cada linha representa um conjunto exclusivo de informações que geralmente representam os dados persistentes de um objeto. Cada entidade tem uma ou mais chaves principais. LineItem_Id é a chave primária de LINEITEM. O suporte a relacionamentos é um recurso específico do fornecedor. O exemplo mostra o modelo lógico e o relacionamento entre as tabelas PRODUCT e LINEITEM. No modelo físico, as relações são geralmente implementadas utilizando as referências de chave estrangeira / chave principal. Se uma entidade estiver relacionada a outra, ela conterá colunas que serão chaves estrangeiras. Colunas de chave estrangeira contêm dados que podem relacionar determinados registros na entidade à entidade relacionada. Há multiplicidade (também chamada de cardinalidade) nos relacionamentos. As cardinalidades comuns são de um para um (1:1), de um para muitos (1:m), de muitos para um (m:1) e de muitos para muitos (m:n). No exemplo, LINEITEM tem um relacionamento 1:1 com PRODUCT, e PRODUCT tem um relacionamento 0:m com LINEITEM. O Modelo de ObjetoUm modelo de objeto contém, entre outras coisas, classes (consulte [UML01] para uma definição completa de um modelo de objeto). As classes definem a estrutura e o comportamento de um conjunto de objetos, às vezes chamados de instâncias de objetos. A estrutura é representada como atributos (valores de dados) e associações (relacionamentos entre classes). A figura a seguir mostra um diagrama simples de classes que possui apenas atributos (dados) das classes.
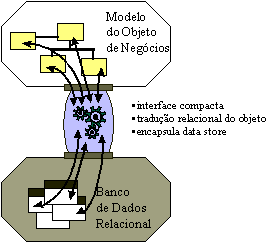
Um Modelo de Objetos (Diagrama de Classes) Um Pedido tem um número (o Número do Pedido) e uma associação com 1 ou mais (1..*) Itens de Linha. Cada Item de Linha tem uma quantidade (a quantidade pedida). O modelo de objetos suporta heranças. Uma classe pode herdar dados e comportamentos de outra classe. Por exemplo, os produtos de SoftwareProduct e HardwareProduct herdam atributos e métodos da classe Produto). Estruturas de PersistênciaA maioria dos aplicativos de negócios utiliza a tecnologia relacional como um armazenamento físico de dados. O desafio dos desenvolvedores de aplicativos orientados a objetos é separar e encapsular suficientemente o banco de dados relacional para que as alterações efetuadas no modelo de dados não "desestruturem" o modelo de objeto e vice-versa. Várias soluções permitem que os aplicativos acessem diretamente os dados relacionais. O desafio está em conseguir uma integração completa entre o modelo de objetos e o modelo de dados. As APIs (Application Programming Interfaces) de bancos de dados têm padrões conhecidos (por exemplo, API ODBC (Open Data Base Connectivity) da Microsoft) e são proprietárias (ligações nativas para bancos de dados específicos). As APIs oferecem serviços de acesso a linguagem de manipulação de dados (DML) que possibilitam o acesso de aplicativos a dados relacionais brutos. Em aplicativos orientados a objetos, os dados devem ser submetidos a uma conversão objeto-relacional antes de serem usados pelo aplicativo. Esse procedimento requer um volume considerável de código do aplicativo para converter resultados brutos da API do banco de dados em objetos do aplicativo. A finalidade do framework objeto-relacional é encapsular genericamente o armazenamento físico de dados e fornecer serviços adequados de conversão de objetos.
A Finalidade do Framework de Persistência Os desenvolvedores de aplicativos gastam mais de 30% de seu tempo implementando o acesso a bancos de dados relacionais em aplicativos orientados a objetos. Se a interface objeto-relacional não for implementada corretamente, o investimento será perdido. A implementação de um framework objeto-relacional captura esse investimento. Esse tipo de framework poderá ser reutilizado em aplicativos subseqüentes, o que reduz o custo de implementação para menos de 10% do custo total da implementação. O custo mais importante a ser considerado durante a implementação de qualquer sistema é o de manutenção. Mais de 60% por cento do custo total de um sistema durante seu ciclo de vida útil pode ser atribuído à manutenção. Um sistema objeto-relacional mal implementado é um pesadelo técnico e financeiro para a manutenção. Características Essenciais de uma Estrutura Relacional de Objetos
Serviços Comuns de Objetos Relacionais
Os aplicativos de objetos relacionais têm apresentado padrões comuns. Os profissionais de TI, que se deparam
repetidamente com lacunas, estão começando a entender e a reconhecer certas estruturas e comportamentos dos aplicativos
objeto-relacional bem-sucedidos. Tais estruturas e comportamentos foram formalizados pelas especificações de Serviços
CORBA de alto nível (que também se aplicam satisfatoriamente a sistemas com base em COM/DCOM). As próximas seções usarão essas categorias para abordar os serviços objeto-relacional comuns. Aconselhamos o leitor a consultar as especificações CORBA adequadas para obter mais detalhes. PersistênciaPersistência é um termo usado para descrever como os objetos utilizam um meio de armazenamento secundário para manter seu estado entre sessões distintas. A persistência permite ao usuário salvar objetos em uma sessão e acessá-los em uma sessão posterior. Quando eles são acessados subseqüentemente, seu estado (por exemplo, atributos) permanecerá igual ao da sessão anterior. Em sistemas multiusuários, talvez não seja esse o caso, já que vários usuários podem acessar e modificar os mesmos objetos. A persistência está inter-relacionada a outros serviços abordados nesta seção. Relacionamentos, simultaneidade e outros aspectos devem ser intencionalmente considerados (e estar consistentes com a especificação CORBA para a decomposição dos serviços). Exemplos de serviços específicos oferecidos pela persistência:
ConsultaO armazenamento de objetos persistentes é pouco útil se não houver um mecanismo para procurar e recuperar objetos específicos. Os recursos de consulta permitem que os aplicativos verifiquem e recuperem objetos com base em vários critérios. As operações básicas de consulta obtidas com um framework de mapeamento objeto-relacional são operações de localização (find) e localização exclusiva (find unique). A operação de localização exclusiva recupera objetos específicos, enquanto a operação de localização retorna um conjunto de objetos com base em um critério de consulta. Os recursos de consulta de armazenamentos de dados variam significativamente. Os armazenamentos de dados baseados em arquivos simples podem implementar operações rígidas de consulta desenvolvidas internamente, enquanto os sistemas relacionais oferecem uma linguagem de manipulação de dados flexível. Os frameworks de mapeamento objeto-relacional expandem o modelo de consulta relacional para que sejam centralizados nos objetos, e não nos dados. Os mecanismos de acesso também são implementados para aproveitar a flexibilidade de consultas relacionais e as extensões específicas do fornecedor (por exemplo, os procedimentos armazenados). Observe que há alguma possibilidade de conflito entre o paradigma do objeto e os mecanismos de consulta que se baseiam no banco de dados: os mecanismos de consulta de banco de dados são orientados por valores de atributos (colunas) em uma tabela. Nos objetos correspondentes, o princípio de encapsulamento impede a visualização dos valores de atributos; eles são encapsulados pelas operações da classe. A razão para o encapsulamento é que facilita a alteração dos aplicativos: é possível alterar a estrutura interna de uma classe sem se preocupar com classes dependentes, desde que as operações publicamente visíveis da classe não sejam alteradas. Um mecanismo de consulta com base no banco de dados depende da representação interna de uma classe, o que efetivamente interrompe o encapsulamento. O desafio do framework é evitar que as consultas alterem os aplicativos mais frágeis. TransaçõesO suporte transacional permite que o desenvolvedor de aplicativos defina uma unidade atômica de trabalho. Na terminologia de bancos de dados, isso significa que o sistema deve ser capaz de aplicar um conjunto de mudanças ao banco de dados ou assegurar que nenhuma mudança seja aplicada. Se todas as operações que ocorrem em uma transação não forem executadas com sucesso, a transação falha como um todo. Os frameworks objeto-relacional devem oferecer às transações, no mínimo, um recurso de confirmação e rollback como o dos bancos de dados relacionais. O design de frameworks objeto-relacional em um ambiente multiusuário pode apresentar vários desafios; por isso, ele deve ser encarado com cuidado. Além dos recursos fornecidos pelo framework de persistência, o aplicativo deve saber como tratar os erros. Quando uma transação falha ou é abortada, o sistema deve ser capaz de restaurar o estado de estabilidade anterior à falha. Geralmente, isso é obtido por meio da leitura de informações sobre o estado anterior obtidas do banco de dados. Dessa forma, ocorre uma perfeita interação entre o framework de persistência e o framework para o tratamento de erros. SimultaneidadeOs sistemas multiusuários orientados a objetos devem controlar o acesso simultâneo a objetos. Quando um objeto é acessado simultaneamente por vários usuários, o sistema deve ter um mecanismo para garantir que as modificações efetuadas no objeto no armazenamento persistente ocorram de maneira previsível e controlada. Os frameworks objeto-relacional podem implementar controles de simultaneidade pessimistas e/ou otimistas.
Todos os aplicativos que utilizam dados compartilhados devem usar a mesma estratégia de simultaneidade. Não é possível combinar o controle de simultaneidade otimista e o pessimista nos mesmos dados compartilhados, pois eles podem ser danificados. Uma estratégia de simultaneidade consistente é melhor aplicada com um framework de persistência. Relacionamentos
Os objetos mantêm relacionamentos com outros objetos. Um objeto Pedido tem muitos objetos Item de Linha. Um objeto
Livro tem muitos objetos Capítulo. Um objeto Funcionário pertence a um objeto Empresa. Nos sistemas relacionais, os
relacionamentos entre as entidades são implementados com referências de chave estrangeira e chave primária. Em sistemas
orientados a objetos, as relações costumam ser explicitamente implementadas por meio de atributos. Se um objeto Pedido
tiver LineItems, então Pedido conterá um atributo denominado lineItems. O atributo lineItems de Pedido conterá muitos
objetos LineItem.
Embora seja teoricamente vantajoso considerar os serviços objeto-relacional comuns separadamente, as implementações do framework serão co-dependentes. Os serviços devem ser implementados com consistência não apenas nas organizações individuais, mas em todos os aplicativos que compartilham os mesmos dados. A framework é o único meio econômico de obter isso. |

© Copyright IBM Corp. 1987, 2006. Todos os Direitos Reservados. |