| Diretriz: Bancos de Dados Relacionais de Engenharia Reversa |
 |
|
| Elementos Relacionados |
|---|
IntroduçãoEsta diretriz descreve as etapas envolvidas em reverter a engenharia de um banco de dados e mapear as tabelas resultantes do Modelo de Dados para as Classes de Design no Modelo de Design. Esse processo pode ser utilizado pelo Designer de Banco de Dados para ocasionar o desenvolvimento de modificações no banco de dados como parte de um ciclo de desenvolvimento evolutivo. O Designer de Banco de Dados precisará gerenciar o processo de engenharia reversa em todo o ciclo de vida de desenvolvimento do projeto. Em muitos casos, o processo de engenharia reversa é desempenhado logo no início do ciclo de vida do projeto e, depois, as alterações no design de dados são gerenciadas de modo incremental, sem a necessidade de desempenhar a engenharia reversa subseqüente do banco de dados. As principais etapas no processo para reverter a engenharia de um banco de dados e transformar os elementos resultantes do Modelo de Dados em elementos do Modelo de Design são mostradas a seguir:
Engenharia Reversa do Banco de Dados RDBMS ou do Script DDL para Gerar um Modelo de DadosO processo de engenharia reversa do banco de dados ou do script DDL (Data Definition Language) geralmente apresenta um conjunto de elementos de modelo (tabelas, visualizações, procedimentos armazenados, etc.) . Dependendo da complexidade do banco de dados, o designer de banco de dados pode precisar particionar os elementos do modelo da engenharia reversa em pacotes de áreas de assunto que contêm conjuntos logicamente relacionados de tabelas. Transformando o Modelo de Dados em Modelo de DesignO procedimento a seguir pode ser utilizado para produzir Classes de Design a partir dos elementos de modelo no Modelo de Dados. A replicação da estrutura do banco de dados em um modelo de classe é um procedimento relativamente simples. O processo listado a seguir descreve o algoritmo para transformar os elementos do Modelo de Dados em elementos do Modelo de Design. A tabela a seguir mostra um resumo do mapeamento geral entre os elementos do Modelo de Design e os elementos do Modelo de Dados.
Há alguns elementos de modelo no Modelo de Dados que não possuem correlação direta no Modelo de Design. Esses elementos incluem os Espaços de Tabelas e o próprio Banco de Dados, que modelam as características de armazenamento físico do banco de dados e são representados como componentes. Um outro item é a visualização do banco de dados, que é uma tabela "virtual" e não tem significado no Modelo de Design. Por último, índices em chaves principais de tabelas e funções do acionador do banco de dados, que são utilizados para otimizar a operação do banco de dados, têm significado apenas no contexto do banco de dados e do Modelo de Dados. Transformar uma Tabela em uma ClassePara cada tabela que você deseja transformar, crie uma classe para representar a tabela. Para cada coluna, crie um atributo na classe com o tipo de dado apropriado. Tente fazer a correspondência mais aproximada possível entre o tipo de dado do atributo e o tipo de dado da coluna associada. Exemplo Considere a tabela de banco de dados Cliente, com a estrutura mostrada na figura a seguir:
Definição da tabela Cliente A partir deste ponto, criamos uma classe, Cliente, com a estrutura mostrada na figura a seguir:
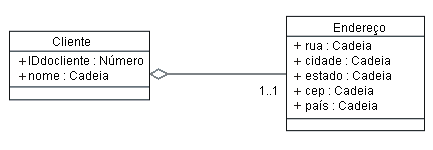
Classe Cliente inicial Nesta classe Cliente inicial, há um atributo para cada coluna na tabela Cliente. Cada atributo possui visibilidade pública, já que qualquer coluna da tabela de origem pode ser consultada. Observe que o ícone "+" listado à esquerda do atributo indica que o atributo é 'público'; por padrão, todos os atributos derivados das tabelas RDBMS devem ser públicos, pois o RDBMS geralmente permite que qualquer coluna seja consultada sem restrição. Identificar Classes Incorporadas ou ImplícitasGeralmente, a classe que resulta do mapeamento direto das classes de tabela contém atributos que podem ser separados em uma outra classe, principalmente nos casos em que os atributos aparecerem em várias classes convertidas. Esses 'atributos repetidos' podem resultar de uma desnormalização das tabelas, por razões de desempenho, ou de um Modelo de Dados muito simplificado. Nesses casos, divida a classe correspondente em duas ou mais classes para representar uma visão normalizada das tabelas. Exemplo Depois de definir a classe Cliente anterior, é possível definir uma classe Endereço que contenha todas as informações de endereço (considerando que haverá outros endereços no sistema), resultando nas classes a seguir:
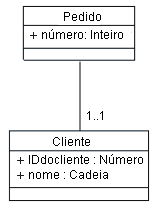
Classe Cliente revisada, com classe Endereço extraída A associação dessas duas classes resulta em uma agregação, já que o endereço do cliente pode ser considerado como parte do cliente. Manipular Relacionamentos de Chave EstrangeiraPara cada relacionamento de chave estrangeira da tabela, crie uma associação entre as classes associadas, removendo o atributo da classe mapeada para a coluna de chave estrangeira. Se a coluna de chave estrangeira tiver sido representada inicialmente como um atributo, remova-a da classe. Exemplo Considere a estrutura da tabela Pedido listada a seguir:
Estrutura da tabela Pedido Na tabela Pedido listada anteriormente, a coluna ID_do_Cliente é uma referência de chave estrangeira; esta coluna contém o valor da chave principal do Cliente associado ao Pedido. Essa representação é mostrada a seguir no Modelo de Design:
Representação dos relacionamentos de chave estrangeira no modelo de design A chave estrangeira é representada como uma associação entre as classes Pedido e Item. Manipular Relacionamentos de Muitos-para-MuitosOs modelos de dados RDBMS representam relacionamentos de muitos-para-muitos que foram chamados de tabela de junção ou tabela de associação. Essas tabelas permitem que esses relacionamentos sejam representados através de uma tabela intermediária, contendo as chaves primárias de duas tabelas diferentes que podem ser associadas. As tabelas de junção são necessárias porque uma referência de chave estrangeira pode conter apenas uma referência a um único valor de chave estrangeira. Quando uma única linha puder ser relacionada a várias outras linhas de uma tabela diferente, a tabela de junção será necessária para associá-las. Exemplo Considere o caso de Produtos, que podem ser fornecidos por qualquer um dos diversos Fornecedores, e de qualquer Fornecedor que possa fornecer fornecer qualquer número de Produtos. As tabelas Produto e Fornecedor possuem a estrutura definida a seguir:
Definições das Tabelas Produtos e Fornecedores Para vincular essas duas tabelas e localizar os produtos oferecidos por um determinado fornecedor, é necessária uma tabela Produto-Fornecedor, definida na tabela a seguir.
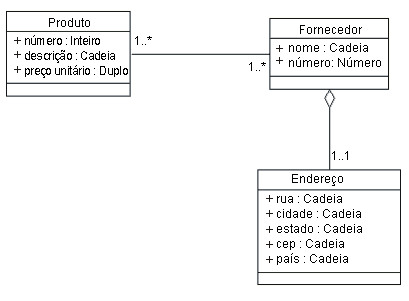
Definição da Tabela Produtos-Fornecedores Esta tabela de junção contém as chaves primárias de produtos e fornecedores, vinculando-os. Uma linha na tabela indicaria que um fornecedor específico oferece um determinado produto. Todas as linhas cuja coluna ID_do_Fornecedor correspondesse a uma identificação específica de fornecedor forneceriam uma listagem de todos os produtos oferecidos por esse fornecedor. No Modelo de Design, essa tabela intermediária é redundante pois um modelo de objeto pode representar diretamente as associações muitos-para-muitos. As classes Fornecedor e Produto e seus relacionamentos são mostrados na figura a seguir, juntamente com a classe Endereço, que é extraída do Fornecedor, de acordo com a discussão anterior.
Representação das Classes Produtos e Fornecedores Introduzir a GeneralizaçãoGeralmente, algumas tabelas terão uma estrutura semelhante. No Modelo de Dados, não há conceito de generalização, portanto não há como representar duas ou mais tabelas com alguma estrutura em comum. Algumas vezes, uma estrutura comum resulta de uma desnormalização de desempenho, como o caso anterior em que a tabela Endereço, extraída em uma classe separada, está 'implícita'. Nos outros casos, as tabelas compartilham características mais fundamentais que podem ser extraídas em uma classe pai generalizada com duas ou mais subclasses. Para localizar oportunidades de generalização, procure por colunas repetidas em várias tabelas, em que as tabelas têm mais semelhanças do que diferenças. Exemplo Considere as tabelas, SoftwareProduct e HardwareProduct, mostradas a seguir:
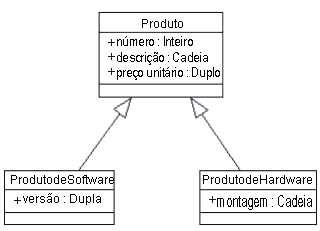
Tabelas SoftwareProduct e HardwareProduct Observe que as colunas destacadas em azul são idênticas; essas duas tabelas compartilham a maior parte de suas definições em comum e diferem somente um pouco. Podemos representar isso extraindo uma classe Produto comum, com SoftwareProduct e HardwareProduct como subclasses do Produto, conforme mostrado na figura a seguir:
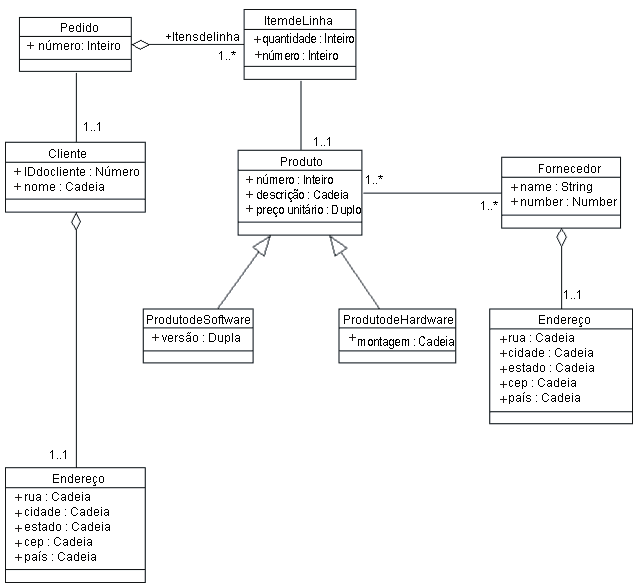
Classes SoftwareProduct e HardwareProduct, mostrando uma generalização da classe Produtos A figura a seguir, que reúne todas as definições de classe, mostra um diagrama de classes consolidado para o sistema Entrada de Pedidos (somente as classes principais).
Diagrama de Classes Consolidado para o Sistema Entrada de Pedidos Replicando o Comportamento do RDBMS no Modelo de DesignReplicar um comportamento é um procedimento mais difícil, pois geralmente os bancos de dados relacionais não são orientados a objetos e não parecem ter nada semelhante às operações em uma classe no modelo de objeto. Os passos a seguir podem ajudar a reconstruir o comportamento das classes identificadas acima:
Organizar Elementos no Modelo de DesignAs Classes de Design criadas a partir das transformações de tabela em classe devem ser organizadas em pacotes de design e/ou subsistemas de design apropriados no Modelo de Design, conforme necessário, com base na estrutura arquitetural geral do aplicativo. Consulte Conceito: Divisão em Camadas e Conceito: Arquitetura de Software para uma visão geral da arquitetura do aplicativo. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

© Copyright IBM Corp. 1987, 2006. Todos os Direitos Reservados. |