A Análise Léxica ou Scanner agrupa caracteres da linguagem fonte em grupos chamados itens léxicos. As classes à que pertencem esses itens são:
PALAVRAS RESERVADAS : DO, IF, etc
IDENTIFICADORES : x, num, etc
SÍMBOLOS DE OPERADORES : <=, +, etc
SÍMBOLOS DE PONTUAÇÃO : ( , ), ; , etc
NÚMEROS : 1024, 105, etc
Por exemplo, em Pascal:
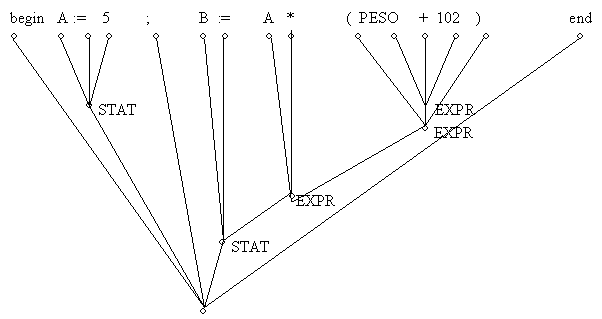
begin A := 5 ; B := A * ( PESO + 102 ) end
A Análise Sintática agrupa os itens léxicos em diversas unidades sintáticas, construindo uma árvore sintática:
A árvores sintática mostra a estrutura grmatical de um programa. Cada um de seus nós representa uma unidade sintática; assim begin, A, :=, 5, ; , ), end
são unidades sintáticas.
Os 3 símbolos do sub-trecho A := 5 compõem, num segundo nível, uma única unidade sintática.
De fato, eles constituem um "statement" do PASCAL. Num 3° nível temos ( PESO + 102); num 4° nível, A * ( PESO + 102 ) que constitui a unidade sinática "expression" do PASCAL, etc. Pode-se notar que há unidades sintáticas compostas de outras unidades (as que estão do 2° nível para baixo), como ( PESO + 102 ), A * ( PESO + 102 ), etc, e outras que são unidades elementares, não compostas de outras, e que estão no 1° nível, que são os itens léxicos.
Dessa maneira, esta estrutura formada pelo "parser" pode ser vista como uma árvores cujas folhas são os itens léxicos.
O "parser" utiliza para a realização de sua tarefa, uma série de regras de sintaxe, que constituem a gramática da Lf. Então, a gramática da Lf é que define, em última instância, as unidades sintáticas e portanto a estrutura sintática do programa fonte. Assim, no ex, vemos que PESO + 102 deve ser reconhecido como uma unidade, antes de se reconhecer a unidade contendo a multiplicação ( '*' ). Isto é, o "parser" 'descobre' que a soma é analisada (e portanto o código correspondente é gerado) antes da multiplicação. Da mesma maneira, as expressões do lado direito das atribuições ( ':=' ) são analisadas (e geradas) antes da atribuição propriamente dita.
Note-se que o "scanner" trabalha com os caracteres do programa fonte, agrupando-os no item léxico conveniente. Assim, as letras 'e', 'n', 'd' são agrupadas na palavra end. Mais ainda, é ele que reconhece o fato de que end é uma palavra reservada da Lf . No caso de uma variável, PESO, as letras 'P', 'E', 'S', 'O' são agrupadas adequadamente, e a palavras assim formada é reconhecida como sendo um "identifier". (No PASCAL, seria na realidade um "variable identifier").
Do mesmo modo, a sequência de caracteres '1', '0', '2' é reconhecida como o n° 102. A sequência ':', '=', como :=, etc.
O "parser" tem também por tarefa o reconhecimento de erros sintáticos, que são construções do programa fonte que não estão de acordo com as regras de formação de unidades sintáticas, como especificado pela gramática. Assim, na sequência A + * B, deve ser detectado um operador aritmético a mais. Após reconhecer um erro de sintaxe, o analisador deve emitir mensagem de erro adequada, e tratar ("recover") esse erro, isto é, continuar a análise do resto do programa. Assim, o erro ocorrido deve influenciar o mínimo possível a análise desse resto.
O "scanner" deve detectar erros léxicos que podem ser, por exemplo, o uso de caracteres não usados pela linguagem, ou nos inteiros com grandeza maior do que a máxima representada no computador.
Toda a análise efetuada pelo compilador além da sintática é denominada comumente por Análise Semântica.
A Análise Semântica engloba, além de outras, 2
partes principais: a Análise de Contexto e a Geração de Código.
Vamos caracterizar a 1a por meio de um exemplo: no comando A:=5,
é necessário fazer a seguinte análise:
Outro tipo comum de erro de contexto é quando se mistura tipos numa mesma expressão.
O gerador de código intermediário usa a estrutura produzida pelo "parser" para criar uma cadeia de instruções simples. Muitos estilos de código intermediário são possíveis. Um estilo comum usa instruções com um operador e um n° pequeno de operandos.
A principal diferença entre código intermediário e código
Assembler é que o 1o não precisa especificar os registradores a serem
usados para cada operação.
A Otimização de Código é uma fase
opcional para melhorar o código intermediário tal que o programa objeto seja
mais rápido e/ou ocupe menos espaço. Sua saída é outro programa em código
intermediário que faz a mesma tarefa do original, mas (talvez) de uma maneira
que economize tempo e/ou espaço.
O gerador de código é a parte do compilador que gera o programa objeto. O código é gerado sempre para determinadas unidades sintáticas, sendo utilizadas informações fornecidas pelo analista de contexto.
Por ex, A:=5 poderia gerar o seguinte código:
LDA =5
STA V+12
onde V+12 é o endereço de A ( no nosso compilador, V+12 indica que A é a 13a variável declarada no programa principal).
Fazer um gerador de código que produza programas objetos
realmente eficientes é uma das partes mais difíceis da construção de um
compilador, tanto do ponto de vista prático como teórico.
O gerenciamento de tabelas ou
"bookkeeping" é a porção do compilador que manipula os nomes usados pelo
programa e registra informações essenciais sobre cada um deles, tal como seu
tipo (inteiro, real, etc). A estrutura de dados usada para registrar essa
informação é chamada Tabelas(s) de Símbolos.
O manipulador de erros é chamado quando uma falha é detectada no programa fonte. Ele deve avisar o programador fornecendo um diagnóstico claro e preciso, e tornar possível a continuação do processo de análise. É desejável que sejam detectados todos os erros numa única compilação.
Ambos gerenciamento de tabelas e manipulador de erros interagem com todas as fases do compilador.
É importante observar que em muitos compiladores uma
parte da análise de contexto é efetuada pelo "scanner", que nesse caso, constrói
e manipula as tabelas, com as variáveis, rótulos, constantes, nomes de
procedimentos, funções e tipos, em lugar da análise de contexto.
Agora, com mais detalhes:
Análise Léxica
O "scanner" é a interface entre o programa fonte e o compilador; ele lê o programa fonte caracter por caracter, juntando-os em unidades atômicas chamadas itens léxicos.
Há 2 tipos de itens: cadeias específicas tal como IF ou ' ; ' e classes de cadeias tal como identificadores, números e rótulos. Para tratar os 2 casos, vamos considerar um item como um par consistindo de 2 partes: o tipo de item e o valor do item. Por conveniência, um item consistindo de uma cadeia específica tal como ' ; ' , será tratado como tendo um tipo (= própria cadeia), mas nenhum valor. Um item tal como um identificador, M, tem um tipo (= identificador) e um valor consistindo da cadeia 'M'.
O "scanner" opera sob o controle do "parser": que pede ao 1o o próximo item sempre que precisar de um. O "scanner" retorna ao "parser" 2 ou mais parâmetros para o "parser", informando o tipo e o valor do item lido. Neste caso, o "scanner" chama uma rotina de bookkeeping que instala o valor atual na tabela de símbolos se ele ainda não está lá..
O 2o parâmetro pode ser o próprio valor ou um ponteiro para a sua posição na tabela de símbolos.
Ex:
IF (5.EQ.MAX) GOTO 100
Pode produzir a seguinte sequência de itens:
If ( [num, 341] eq [id, 729] ) goto [rot., 554]
Onde a tabela de símbolos conteria

Veja mais:
Análise Sintática
O "parser" tem 2 funções:
1 - Verifica se os itens recebidos do "scanner" aparecem numa ordem tal que seja permitida pela especificação da Lf. Ele também impõe aos itens uma estrutura do tipo árvore, que é usada pelas fases subsequentes do compilador.
Por exemplo: se um programa A|GO| contém a expressão
A */ B
Ao encontrar /, o parser detecta uma situação de erro, devido à
presença de 2 operadores binários adjacentes violar as regras de formação de
expressões no A|GO|.
2 - A 2a função é tornar explícita a estrutura hierárquica da cadeia de itens, identificando quais partes da cadeia de itens devem ser agrupadas juntas.
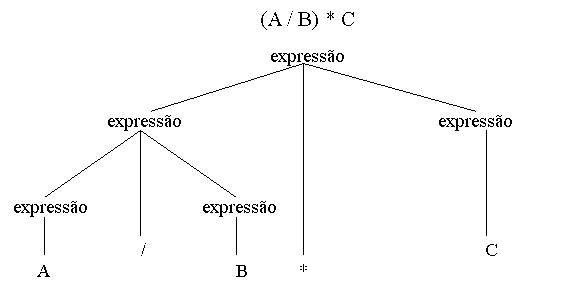
Por exemplo: a expressão
A / B * C
tem 2 possíveis interpretações:
Cada uma dessas 2 interpretações pode ser representada em
termos de uma árvore sintática, um diagrama que exibe a estrutura
sintática da expressão:
a)
b)
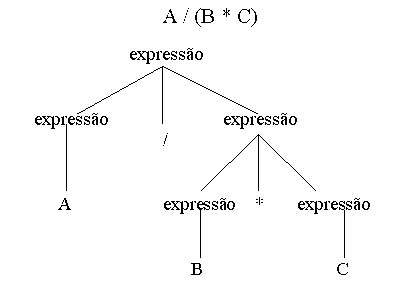
Note que os operandos da 1a operação a ser efetuada se encontram num nível mais baixo da árvore.
A especificação da linguagem deve nos dizer qual das interpretações acima, deve ser usada, e em geral, que estrutura hierárquica cada programa fonte possui.
Essas regras formam a especificação sintática de uma linguagem de programação.
[As gramáticas livres de contexto são particularmente apropriadas para especificar a estrutura sintática de uma linguagem].
"Bookkeeping "
Um compilador precisa coletar informações sobre todos os objetos que aparecem no programa fonte. Por exemplo, ele deve saber se uma variável representa um n° inteiro ou um n° real; qual o tamanho de um array; quantos argumentos uma função espera, etc.
A informação sobre os objetos pode ser explícita como nas declarações, ou implícita como na 1a letra de um identificador ou no contexto em que um identificador é usado. Por exemplo, em Fortran, A[I] é uma chamada de função se A não foi declarado como um array.
As informações sobre os objetos são coletadas pelas 1as fases da compilação - análises léxica e sintática - e introduzidas na tabela de símbolos (T.S.). Por exemplo: quando o "scanner" vê um identificador MAX, ele deve introduzir o nome MAX na T.S., se ele já não estiver lá, e produzir como saída um item cuja componente valor é um índice para essa entrada na T.S. Se o "parser" reconhece uma declaração INTEGER MAX, sua ação é anotar na T.S. que MAX tem tipo "inteiro". Nenhum código intermediário é gerado por esse comando.
O termo análise semântica é aplicada à determinação do tipo de resultados intermediários; à verificação de que os argumentos são de tipos legais para aplicação de um operador; e a determinação da operação denotada pelo operador (exemplo: + poderia denotar adição em ponto fixo ou flutuante, ou 'or' lógico e possivelmente outras operações).
A análise semântica pode ser feita durante a análise sintática,
a geração de código intermediário ou na fase final de geração de código.
Veja mais:
Manipulação de Erros
Uma das funções mais importantes do compilador é a detecção e o aviso de erros no programa fonte. As mensagens de erro devem permitir ao programador determinar exatamente quais e onde os erros ocorreram.
Eles podem ser encontrados durante todas as fases do compilador; por exemplo;
Uma vez que o erro é detectado, o compilador deve modificar a
entrada da fase que o detectou, tal que essa possa continuar processando suas
entradas, procurando subsequentes erros. Um bom manipulador de erros é difícil
porque certos erros podem ocultar erros subsequentes; outros erros, se não
manipulados adequadamente, podem gerar uma avalanche de falsos erros.