- Visão geral sobre padrões frequentes
- Aplicações
- Alguns trabalhos recentes
março – 2016
Sumário
Visão geral sobre padrões frequentes
Mineração de dados é uma maneira sistemática de organizar dados para facilitar a extração de informações úteis e desconhecidas
- Mineração de regras de associação é uma das formas mais efetivas/populares
- Introduzida para analisar padrões de consumo em supermercados
- Ideia é identificar itens que são frequentemente comprados em uma única transação (padrões frequentes)
Aplicações
- Marketing
- Recuperação de informação
- Bio/Quimio-informática
- Sistemas de recomendação
- Sistemas de classificação

(a) Marketing
Aplicações – Sistemas de recomendação
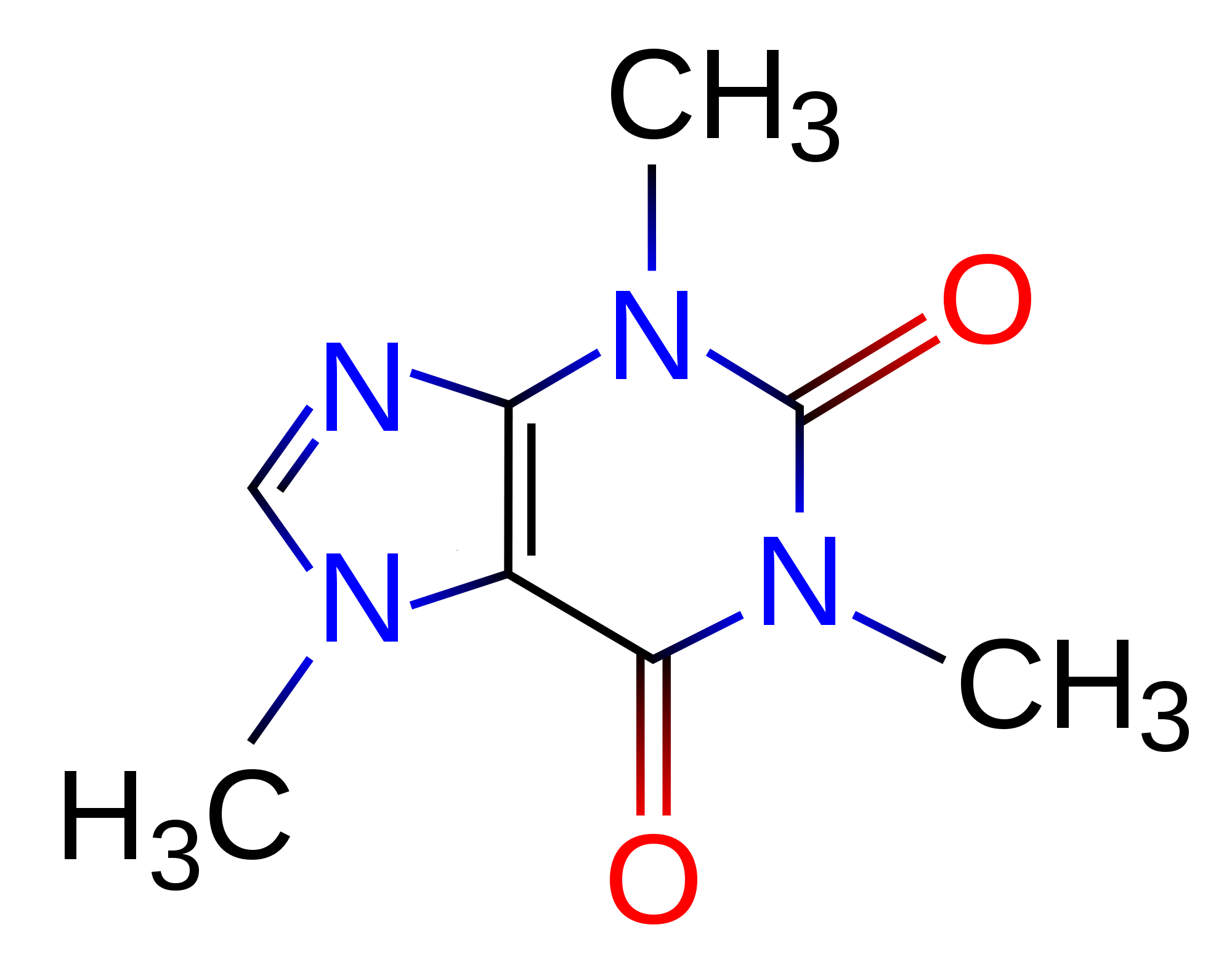
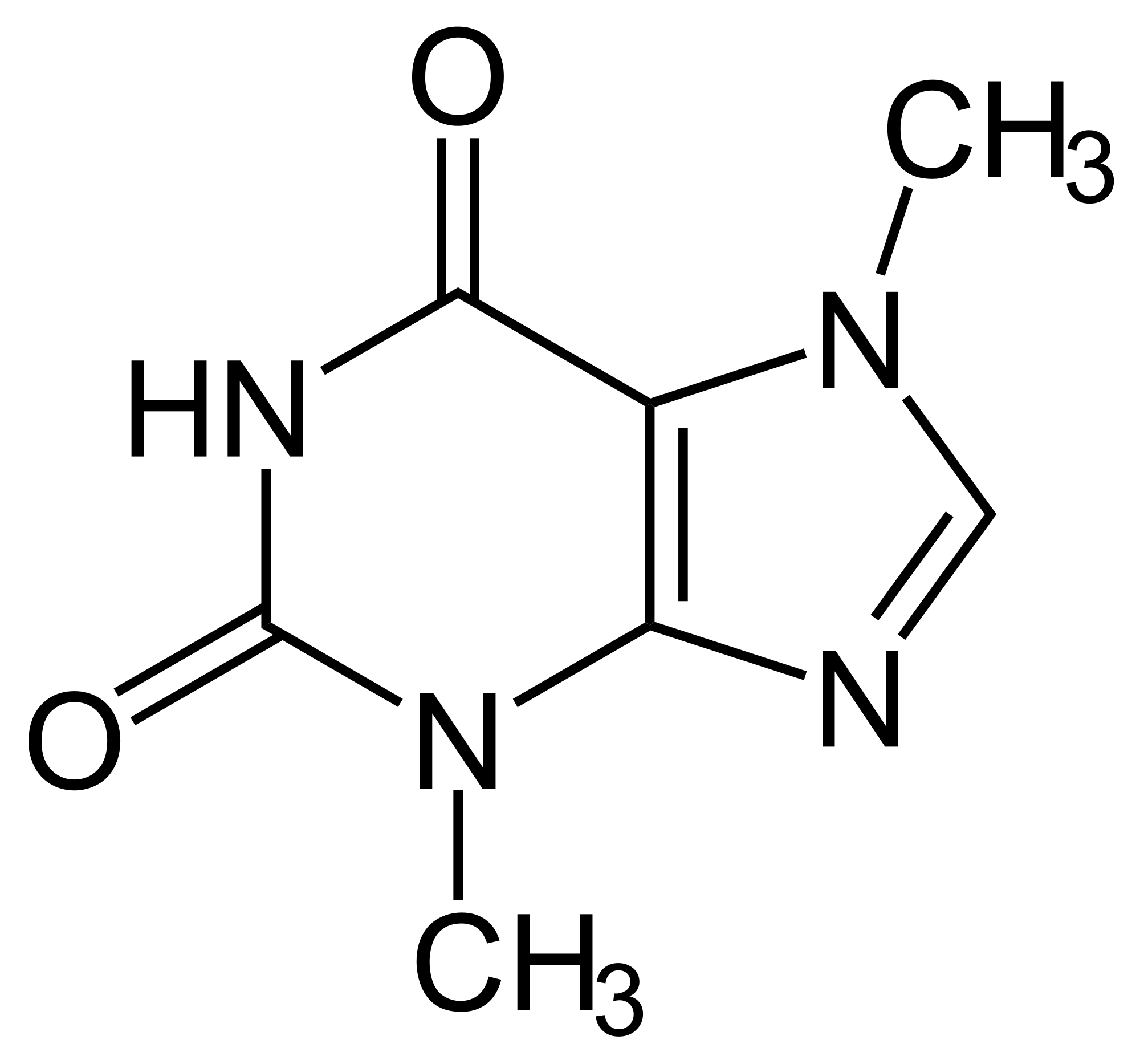
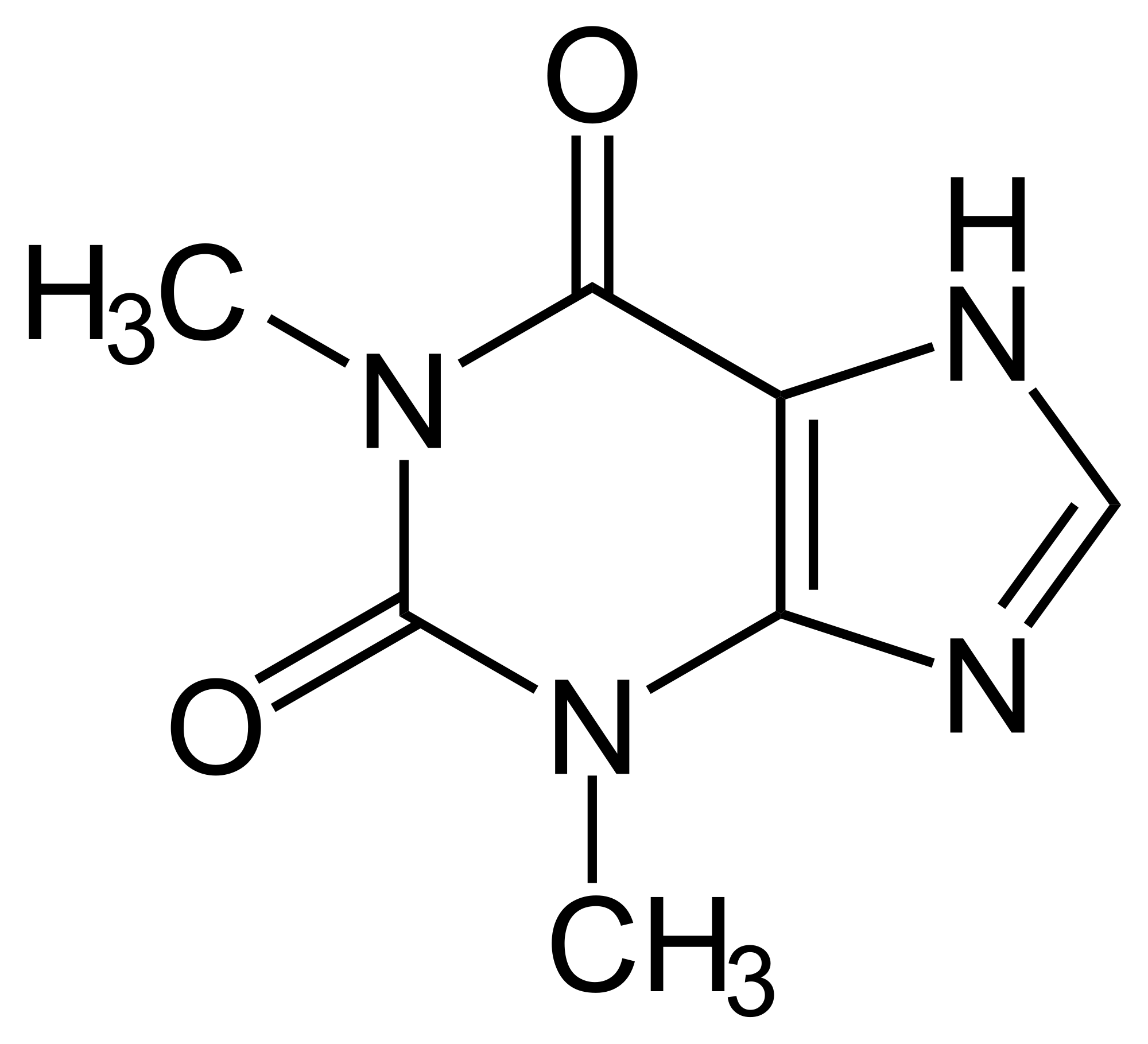
Aplicações – Quimioinformática (mineração de grafos)
Cafeína |
Teobromina (Choc) |
Teofilina (Asma) |
|---|---|---|
 |
 |
 |
Desafios
- Minerar grandes volumes de dados
- Adaptar/Desenhar algoritmos eficientes para problemas específicos
- Auxiliar especialistas na aplicação desses algoritmos
Mineração de padrões discriminativos
Problema: encontrar padrões que sejam frequentes em um grupo, e que sejam infrequente nos demais.
- Aplicações:
- Caracterização de doenças (sadio x doente) (Yeoh et al., 2002)
- E-learning (Romero et al., 2009)
- Análise de tráfego em cidades (Lavrac et al., 2004)
Possibilidades a explorar
- Uso de novas tecnologias para paralelização massiva (GPUs, Xeon-Phi, MapReduce …)
- Uso de heurísticas (e.g. algoritmos genéticos)
- Aplicações diversas
Alguns trabalhos recentes
Arefin AS, Vimieiro R, Riveros C, Craig H, Moscato P (2014) An Information Theoretic Clustering Approach for Unveiling Authorship Affinities in Shakespearean Era Plays and Poems. PLoS ONE 9(10): e111445. doi:10.1371/journal.pone.0111445

Alguns trabalhos recentes
Milioli, H, Vimieiro, R, Riveros C, Tishchenko, I, Berretta, R, Moscato P (2015) The discovery of novel biomarkers improves breast cancer intrinsic subtype prediction and reconciles the labels in the METABRIC data set. PLoS ONE (em revisão)

Perguntas?
Obrigado!
Referências
Yeoh, E-J; et al. Classification, subtype discovery, and prediction of outcome in pediatric acute lymphoblastic leukemia by gene expression profiling, Cancer Cell, Volume 1, Issue 2, March 2002, Pages 133-143, ISSN 1535-6108, http://dx.doi.org/10.1016/S1535-6108(02)00032-6.
Romero, C.; González, P.; Ventura, S.; del Jesus, M.J.; Herrera, F. Evolutionary algorithms for subgroup discovery in e-learning: A practical application using Moodle data, Expert Systems with Applications, Volume 36, Issue 2, Part 1, March 2009, Pages 1632-1644, ISSN 0957-4174, http://dx.doi.org/10.1016/j.eswa.2007.11.026.
Lavrač, N., Kavšek, B., Flach, P. A., & Todorovski, L. (2004). Subgroup discovery with CN2-SD. Journal of Machine Learning Research, 5, 153 - 188.
Referências
Arefin AS, Vimieiro R, Riveros C, Craig H, Moscato P (2014) An Information Theoretic Clustering Approach for Unveiling Authorship Affinities in Shakespearean Era Plays and Poems. PLoS ONE 9(10): e111445. doi:10.1371/journal.pone.0111445
Vimieiro, R. and P. Moscato (2014). A new method for mining disjunctive emerging patterns in high-dimensional datasets using hypergraphs. Information Systems 40, 1-10.