| Diretriz: Bancos de Dados Relacionais de Engenharia Avançada |
 |
|
| Elementos Relacionados |
|---|
IntroduçãoEsta diretriz descreve os métodos para mapear classes de design persistentes no Modelo de Design para tabelas no Modelo de Dados. Transformando Elementos do Modelo de Design em Elementos do Modelo de DadosAs classes persistentes do modelo de design podem ser transformadas em tabelas no Modelo de Dados. A tabela a seguir mostra um resumo do mapeamento entre os elementos do Modelo de Design e os elementos do Modelo de Dados.
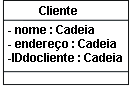
Mapeando Classes Persistentes para TabelasAs classes persistentes no Modelo de Design representam as informações que o sistema deve armazenar. Conceitualmente, essas classes podem se assemelhar a um design relacional. (Por exemplo, as classes no Modelo de Design podem ser refletidas, de certa forma, como entidades no esquema relacional.) Entretanto, à medida que um projeto passa da elaboração para a construção, as metas do Modelo de Design e do Modelo de Dados Relacional divergem. Essa divergência ocorre porque o objetivo do desenvolvimento do banco de dados relacional é normalizar os dados, enquanto a meta do Modelo de Design é encapsular comportamentos cada vez mais complexos. A divergência entre estas duas perspectivas, dados e comportamento, gera a necessidade de mapeamento entre elementos relacionados nos dois modelos. Em um banco de dados relacional gravado na terceira forma normal, cada linha das tabelas - cada "tupla" - é considerada um objeto. Uma coluna em uma tabela equivale a um atributo persistente de uma classe. (Observe que uma classe persistente pode ter atributos transientes.) Portanto, no simples caso de não haver associações com outras classes, o mapeamento entre os dois mundos é simples. O tipo de dados do atributo corresponde a um dos tipos de dados permitidos para colunas. Exemplo A seguinte classe Cliente:
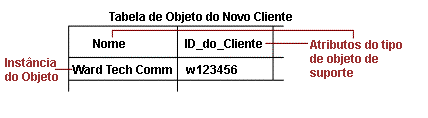
quando modelada no RDBMS é convertida em uma tabela denominada Cliente, com as colunas Customer_ID, Nome e Endereço. Uma instância dessa tabela pode ser visualizada como:
Atributos e Chaves PersistentesPara cada atributo persistente, deve-se fazer perguntas para obter informações adicionais que serão utilizadas para modelar adequadamente o objeto persistente em um Modelo de Dados relacional. Por exemplo:
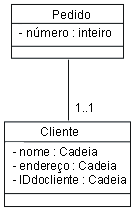
Mapeando Associações entre Objetos Persistentes para o Modelo de DadosAs associações entre dois objetos persistentes são realizadas como chaves estrangeiras para os objetos associados. Uma chave estrangeira é uma coluna em um tabela que contém o valor da chave primária do objeto associado. Exemplo: Suponha que exista a seguinte associação entre Pedido e Cliente:
Quando estas informações são mapeadas para tabelas relacionais, o resultado é uma tabela Pedido e uma tabela Cliente. A tabela Pedido possui colunas para os atributos listados, além de uma coluna adicional denominada Customer_ID, que contém referências de chave estrangeira para a chave principal da linha associada na tabela Cliente. Para um determinado Pedido, a coluna Customer_ID contém o identificador do Cliente ao qual o Pedido está associado. As chaves estrangeiras permitem que o RDBMS una informações relacionadas. Mapeando Associações de Agregação para o Modelo de DadosA agregação também é modelada usando relacionamentos de chaves estrangeiras. Exemplo: Suponha que exista a seguinte associação entre Pedido e Item de Linha:
Quando estas informações são mapeadas para tabelas relacionais, o resultado é uma tabela Pedido e uma tabela Line_Item. A tabela Line_Item possui colunas para os atributos listados, além de uma coluna adicional denominada Order_ID, que contém uma referência de chave estrangeira para a linha associada na tabela Pedido. Para um determinado Item de Linha, a coluna Order_ID contém o Order_ID do Pedido ao qual o Item de Linha está associado. As chaves estrangeiras permitem que o RDBMS otimize operações de união. Além disso, é importante implementar uma restrição de exclusão em cascata que forneça integridade referencial no Modelo de Dados. Uma vez feito isso, sempre que o Pedido for excluído, todos os seus Itens de Linha também serão excluídos. Modelando Relacionamentos de Generalização no Modelo de DadosO Modelo de Dados relacional padrão não suporta a herança de modelagem de um modo direto. Várias estratégias podem ser utilizadas para modelar a herança. Elas podem ser resumidas conforme a seguir:
Modelando Associações de Muitos-para-Muitos no Modelo de DadosUma técnica padrão na modelagem relacional é utilizar uma entidade de interseção para representar associações de muitos-para-muitos. A mesma abordagem pode ser aplicada aqui: Uma tabela de interseção é utilizada para representar a associação. Exemplo: Se Fornecedores podem oferecer muitos Produtos e um Produto pode ser oferecido por vários Fornecedores, a solução é criar uma tabela Fornecedor/Produto. Esta tabela deve conter somente as chaves principais das tabelas Fornecedor e Produto e serve para vincular os Fornecedores a seus Produtos. Não há uma tabela equivalente a essa no Modelo de Objeto; ela é utilizada apenas para representar as associações no Modelo de Dados relacional. Refinando o Modelo de DadosDepois que as classes de design foram transformadas em tabelas e nos relacionamentos apropriados no Modelo de Dados, o modelo é refinado, conforme necessário, para implementar a integridade referencial e otimizar o acesso a dados por meio de visualizações e procedimentos armazenados. Para obter informações adicionais, consulte Diretriz: Modelo de Dados. Engenharia de Redirecionamento do Modelo de DadosA maioria das ferramentas de design de aplicativo suportam a geração de scripts DDL (Data Definition Language) a partir de Modelos de Dados e/ou a geração do banco de dados a partir do Modelo de Dados. A engenharia de redirecionamento do banco de dados precisa ser planejada como parte das tarefas gerais de desenvolvimento e integração de aplicativos. A cronometragem e a freqüência para a engenharia de redirecionamento do banco de dados a partir do Modelo de Dados depende da situação específica do projeto. Para novos projetos de desenvolvimento de aplicativo que estejam criando um novo banco de dados, pode ser necessário utilizar a engenharia de redirecionamento inicial como parte do trabalho para implementar uma versão arquitetural estável do aplicativo no final da fase de elaboração. Em outros casos, pode ser necessário utilizar a engenharia de redirecionamento inicial logo no início das iterações da fase de construção. Os tipos de elementos de modelo no Modelo de Dados que podem utilizar a engenharia avançada variam, dependendo das ferramentas de design específicas e do RDBMS utilizado no projeto. Em geral, os principais elementos estruturais do Modelo de Dados, incluindo tabelas, visualizações, procedimentos armazenados, acionadores e índices podem utilizar a engenharia de redirecionamento no banco de dados. |
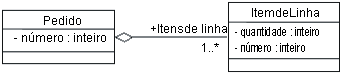
© Copyright IBM Corp. 1987, 2006. Todos os Direitos Reservados. |