| Diretriz: Modelo de Dados |
 |
|
| Elementos Relacionados |
|---|
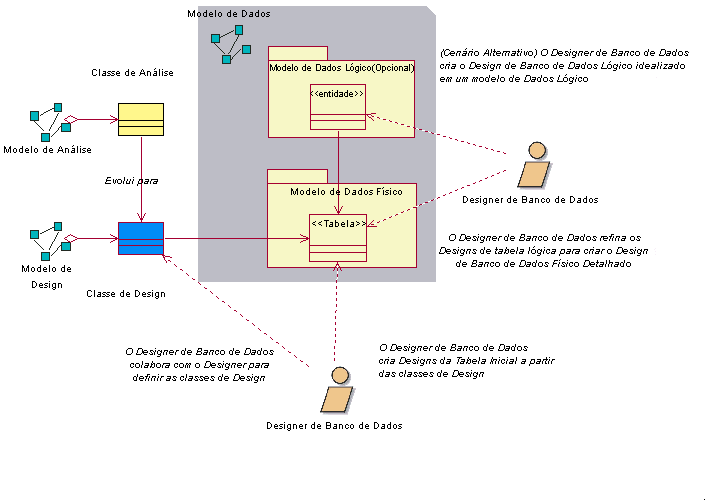
Visão GeralModelos de Dados são utilizados para projetar a estrutura dos data stores persistentes utilizados pelo sistema. O perfil UML (Unified Modeling Language) para o design de banco de dados fornece aos designers do banco de dados um conjunto de elementos de modelagem que podem ser utilizados para desenvolver o design detalhado de tabelas no banco de dados e modelar o layout de armazenamento físico do banco de dados. O perfil do banco de dados UML também fornece construções para modelar a integridade referencial (restrições e acionadores), bem como procedimentos armazenados utilizados para gerenciar o acesso ao banco de dados. Os Modelos de Dados podem ser construídos no nível de aplicativo corporativo, departamental ou individual. Os Modelos de Dados nos níveis corporativo e departamental podem ser utilizados para fornecer definições padrão para as principais entidades de negócios (como cliente e funcionário) que serão utilizadas por todos os aplicativos em um negócio ou uma unidade de negócios. Esses tipos de Modelos de Dados também podem ser utilizados para definir qual sistema na corporação é o "proprietário" dos dados para uma entidade de negócios específica e quais outros sistemas são usuários (assinantes) dos dados. Esta diretriz descreve os elementos do modelo do perfil UML para a modelagem de banco de dados utilizada na construção de um Modelo de Dados para um banco de dados relacional. Como existem inúmeras publicações sobre teoria geral de bancos de dados, essa área não é abrangida. Para obter informações de segundo plano sobre Modelos de Dados e Modelos de Objetos relacionais, consulte Conceito: Bancos de Dados Relacionais e Orientação de Objetos. Nota: As representações de modelagem de dados contidas nesta diretriz baseiam-se na UML 1.3. Quando esta diretriz foi desenvolvida, o perfil de modelagem de dados UML 1.4 não estava disponível. Estágios de Modelagem de DadosConforme descrito em [NBG01], há três estágios gerais no desenvolvimento de um Modelo de Dados: conceitual, lógico e físico. Estes estágios de modelagem de dados refletem os diferentes níveis de detalhes no design dos mecanismos de armazenamento de dados persistentes e de recuperação do aplicativo. Uma discussão de modelagem de dados conceituais é fornecida em ConceitosModelagem de Dados Conceituais. Resumos de modelagem de dados físicos e lógicos são fornecidos nas próximas duas seções desta diretriz. Modelagem de Dados LógicosNa modelagem de dados lógicos, o Designer de Banco de Dados preocupa-se em identificar as principais entidades e os relacionamentos que capturam as informações críticas que o aplicativo precisa para persistir no banco de dados. Durante as tarefas Análise de Caso de Uso, Design de Caso de Uso e Design de Classe, o Designer de Banco de Dados e o Designer devem trabalhar juntos para assegurar que os designs de evolução das classes de análise e design para o aplicativo suportem adequadamente o desenvolvimento do banco de dados. Durante a tarefa Design de Classe, o designer de banco de dados e o designer devem identificar o conjunto de classes no Modelo de Design que precisará persistir dados no banco de dados. Esse conjunto de classes persistentes no Modelo de Design fornece uma Visualização de Modelo de Dados que, embora diferente do Modelo de Dados Lógicos tradicional, atende a muitas das mesmas necessidades. As classes persistentes no Modelo de Design funcionam da mesma maneira que as entidades tradicionais no Modelo de Dados Lógicos. Essas classes de design refletem exatamente os dados que devem ser persistidos, incluindo todas as colunas de dados (atributos) que devem ser persistidas e os principais relacionamentos. Isso torna essas classes de design um excelente ponto inicial para o design de banco de dados físico. A criação de um Modelo de Dados Lógico separado é uma opção. No entanto, no melhor caso isso acabaria capturando as mesmas informações de uma forma diferente. No pior isso não ocorreria e, portanto, no final poderia não atender às necessidades de negócios do aplicativo. Particularmente, se o banco de dados destina-se a servir um único aplicativo, a visualização dos dados do aplicativo pode ser o melhor ponto inicial. O designer de banco de dados cria tabelas a partir desse conjunto de classes de design persistente para formar um Modelo de Dados Físicos. Além disso, podem existir situações que exijam que o designer de banco de dados crie um design idealizado do banco de dados que seja independente do design de aplicativo. Nesse caso, o design de banco de dados lógico é representado em um Modelo de Dados Lógicos separado que faz parte do Produto de Trabalho: Modelo de Dados geral. Esse Modelo de Dados Lógicos representa as principais entidades lógicas e seus relacionamentos, que são necessários para atender aos requisitos do sistema para persistência de dados consistentes com a arquitetura geral do aplicativo. O Modelo de Dados Lógicos pode ser construído utilizando os elementos de modelagem do perfil da UML para o design de banco de dados descrito nas seções posteriores desta diretriz. Para projetos que utilizam esta abordagem, a colaboração estrita entre os designers de aplicativo e de banco de dados é absolutamente crítica para o desenvolvimento bem-sucedido do design de banco de dados. O Modelo de Dados Lógicos pode ser refinado aplicando-se as regras padrão para normalização, conforme definido em Conceito: Normalização antes de desenvolver os elementos do Modelo de Dados Lógicos para criar o design físico do banco de dados. A figura a seguir representa a abordagem principal de utilização das classes de Modelo de Design como a origem das informações lógicas do design de banco de dados para criar um Modelo de Dados Físicos inicial. Também ilustra a abordagem alternativa de utilização de um Modelo de Dados Lógicos separado.
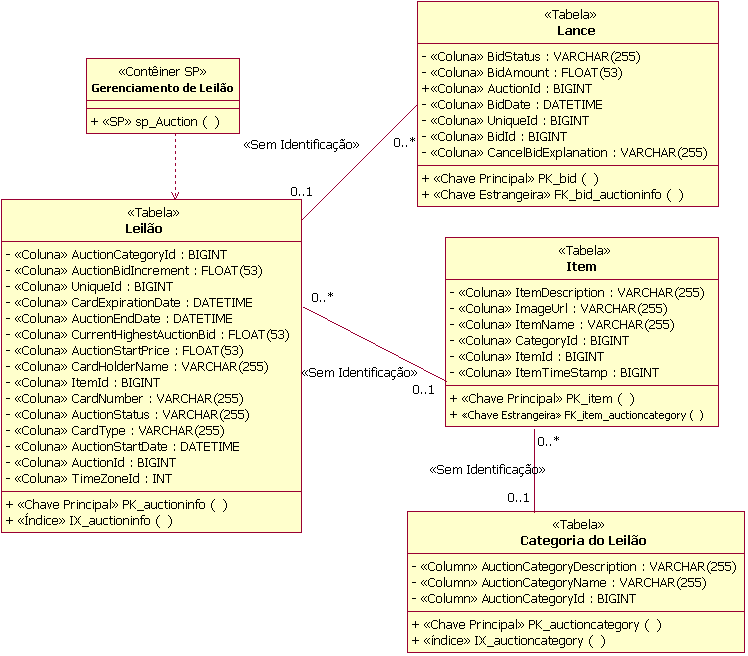
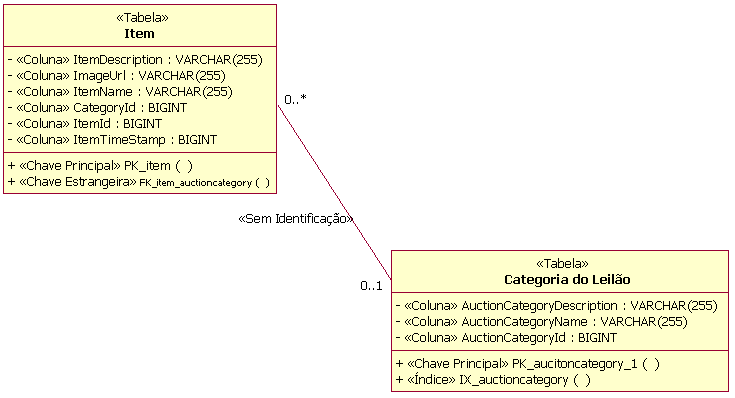
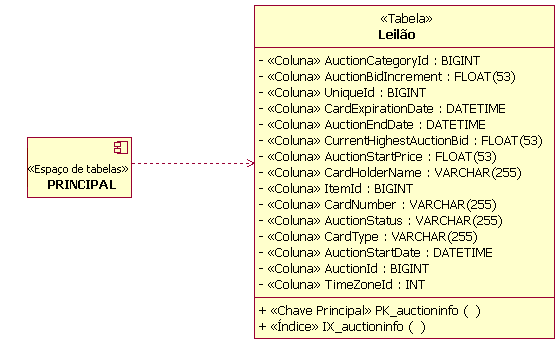
Abordagens de Modelagem de Dados Lógicos Modelagem de Dados FísicosA modelagem de dados físicos é o estágio final do desenvolvimento no design de banco de dados. O Modelo de Dados Físicos consiste nos designs detalhados das tabelas do banco de dados e seus relacionamentos criados inicialmente a partir das classes de de design persistentes e seus relacionamentos. A mecânica para desempenhar a transformação das classes de Modelo de Design em tabelas é descrita em Diretriz: Bancos de Dados Relacionais de Engenharia de Redirecionamento. O Modelo de Dados Físicos faz parte do Modelo de Dados; ele não é um artefato separado. As tabelas no Modelo de Dados Físicos possuem colunas bem definidas, além de chaves e índices, conforme necessário. As tabelas também podem ter acionadores definidos, conforme necessário, para suportar a funcionalidade do banco de dados e a integridade referencial do sistema. Além das tabelas, os procedimentos armazenados foram criados, documentados e associados ao banco de dados no qual residirão. O diagrama a seguir mostra um exemplo de alguns elementos do Modelo de Dados Físicos. Este modelo de exemplo é uma parte do Modelo de Dados Físicos de um aplicativo de leilão on-line fictício. Ele representa quatro tabelas (Leilão, Lance, Item e Categoria de Leilão), juntamente com um procedimento armazenado (sp_Auction) e sua classe de contêiner (AuctionManagement). A figura também representa as colunas de cada tabela, as restrições de chave principal e chave estrangeira e os índices definidos para as tabelas.
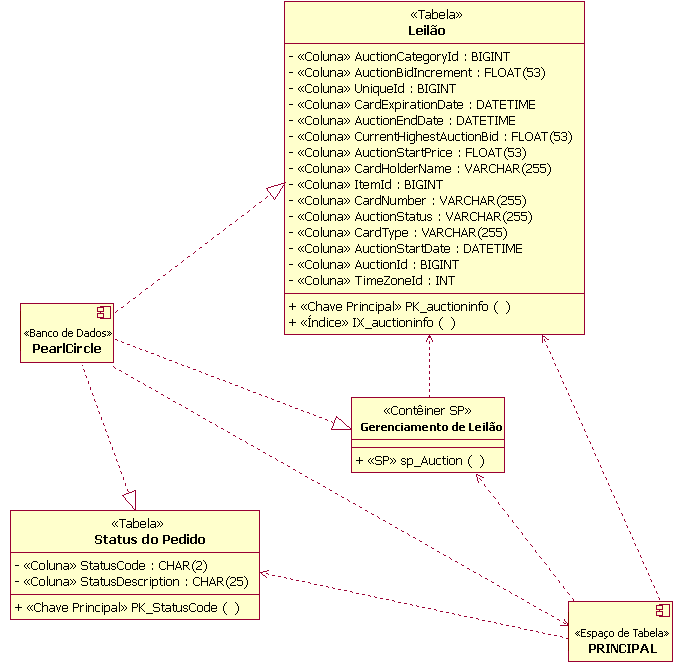
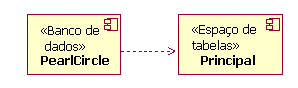
Exemplo de Elementos do Modelo de Dados (Físicos) O Modelo de Dados Físicos também contém mapeamentos das tabelas para unidades de armazenamento físico (espaços de tabelas) no banco de dados. A figura a seguir mostra um exemplo deste mapeamento. Neste exemplo, as tabelas Leilão e OrderStatus são mapeadas para um espaço de tabelas denominado PRINCIPAL. O diagrama também ilustra a modelagem da realização das tabelas no banco de dados (nomeado PearlCircle neste exemplo).
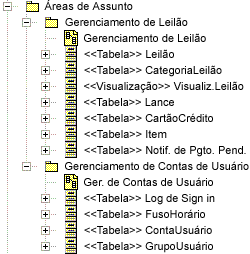
Exemplo de Elementos do Modelo de Armazenamento de Dados Em projetos nos quais um banco de dados já existe, um designer de banco de dados pode reverter a engenharia do banco de dados existente para preencher o Modelo de Dados Físicos. Consulte Diretriz: Bancos de Dados Relacionais de Engenharia Reversa para obter informações adicionais. Elementos do Modelo de DadosEsta seção descreve as diretrizes gerais de modelagem para cada elemento principal do Modelo de Dados com base no perfil UML para modelagem do banco de dados. Uma descrição breve de cada elemento do modelo é seguida por uma ilustração de exemplo do elemento do modelo UML. A seção Relacionamentos desta diretriz inclui uma descrição do uso dos elementos de modelo. PacoteOs pacotes UML padrão são utilizados para agrupar e organizar elementos do Modelo de Dados. Por exemplo, os pacotes poderiam ser definidos para organizar o Modelo de Dados em Modelos de Dados Lógicos e Físicos. Os pacotes também poderiam ser utilizados para identificar grupos logicamente relacionados de tabelas no Modelo de Dados que constituem as principais "áreas de assunto" de dados de importância para o domínio de negócios do aplicativo que está sendo desenvolvido. A figura a seguir mostra um exemplo de dois pacotes de área de assunto (Gerenciamento de Leilão e Gerenciamento de Conta do Usuário) utilizados para organizar visualizações e tabelas no Modelo de Dados.
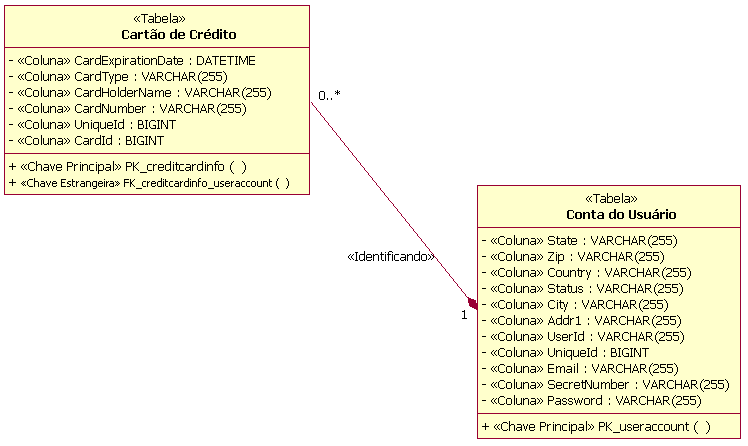
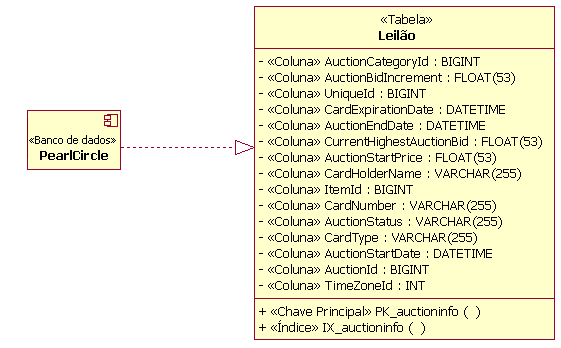
Exemplo de Pacotes de Área de Assunto TabelaNo perfil UML para modelagem do banco de dados, uma tabela é modelada como uma classe com um estereótipo de <<Tabela>>. As colunas na tabela são modeladas como atributos com o estereótipo de <<coluna>>. Uma ou mais colunas podem ser designadas como uma chave principal para fornecer entradas de linhas exclusivas na tabelas. As colunas também podem ser designadas como chaves estrangeiras. As chaves principais e as chaves estrangeiras possuem restrições associadas que são modeladas como operações estereotipadas como <<Chave Principal>> e <<Chave Estrangeira>>, respectivamente. A figura a seguir representa a estrutura de uma tabela de exemplo utilizada para gerenciar informações sobre itens vendidos em leilão em um sistema de leilões on-line fictício.
Exemplo de Tabela As tabelas podem estar relacionadas a outras tabelas pelos tipos de relacionamentos a seguir:
A seção Relacionamentos desta diretriz fornece exemplos de como esses relacionamentos são utilizados. As informações sobre como esses tipos de relacionamentos podem ser mapeados para os elementos do Modelo de Design aparecem em Diretriz: Bancos de Dados Relacionais de Engenharia Reversa. AcionadorUm acionador é uma função de procedimentos projetada para ser executada como resultado de alguma ação na tabela na qual o acionador reside. Um acionador é definido para ser executado quando uma linha na tabela é inserida, atualizada ou excluída. Além disso, um acionador é projetado para ser executado antes ou após a execução do comando da tabela. Os acionadores são definidos como operações em uma tabela. As operações são estereotipadas como <<Acionador>>.
Exemplo de Acionador ÍndiceOs índices são utilizados como mecanismos para permitir acesso mais rápido às informações quando colunas específicas são utilizadas para procurar a tabela. Um índice é modelado como uma operação na tabela com um estereótipo de <<índice>>. Os índices poderiam ser designados como exclusivos e como armazenados em cluster ou não armazenados em cluster. Os índices armazenados em cluster são utilizados para forçar a ordem das linhas de dados na tabela a ser alinhada com a ordem dos valores de índice. Um exemplo de uma operação de índice (IX_auctioncategory) é mostrado na figura a seguir.
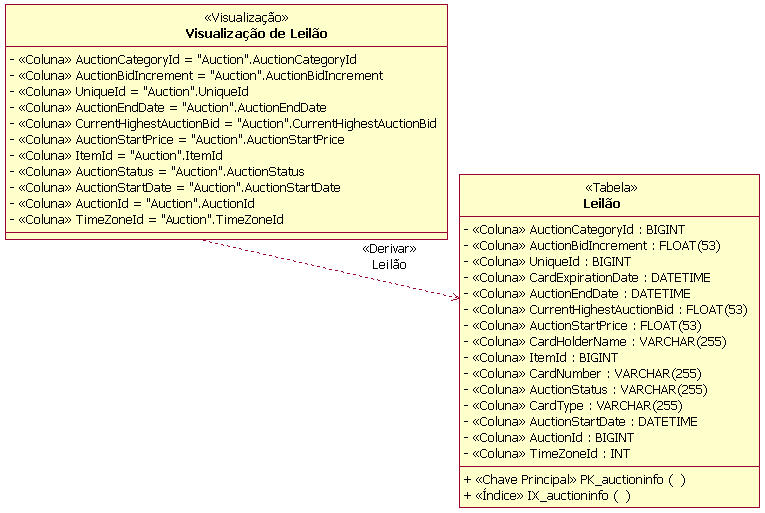
Exemplo de Índice VisualizaçãoUma visualização é uma tabela virtual sem armazenamento persistente independente. Uma visualização possui as características e os comportamentos de uma tabela e acessa os dados nas colunas a partir das tabelas com as quais a visualização possui relacionamentos definidos. As visualizações são utilizadas para fornecer acesso mais eficiente às informações de uma ou mais tabelas e também podem ser utilizadas para aplicar regras de negócios para restringir o acesso a dados nas tabelas. No exemplo a seguir, uma AuctionView foi definida como uma "visualização" de informações na tabela Leilão mostrada na seção de modelagem de dados físicos desta diretriz. As visualizações são modeladas como classes com o estereótipo de <<visualização>>. Os atributos da classe de visualização são as colunas das tabelas referenciadas pela visualização. Os datatypes das colunas na visualização são herdados das tabelas com uma dependência definida com a visualização.
Exemplo de Visualização DomínioUm domínio é um mecanismo utilizado para criar datatypes definidos pelo usuário que podem ser aplicados a colunas em várias tabelas. Um domínio é modelado como uma classe com o estereótipo <<Domínio>>. No exemplo a seguir, um domínio foi definido para um CEP "CEP + 4".
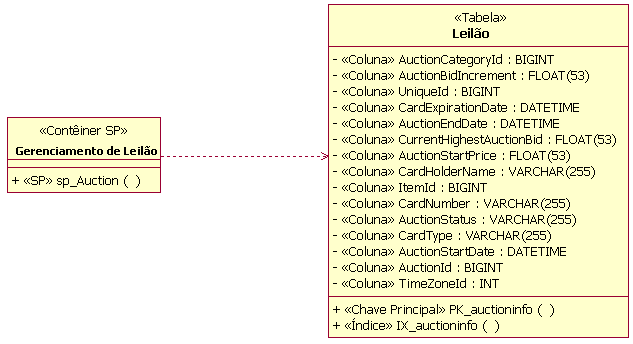
Exemplo de Domínio Contêiner de Procedimentos ArmazenadosUm contêiner de procedimentos armazenados é um agrupamento de procedimentos armazenados no Modelo de Dados. Ele é criado como uma classe UML com o estereótipo de <<Contêiner de SP>>. Vários contêineres de procedimentos armazenados podem ser criados em um design de banco de dados. Cada um deles deve ter pelo menos um procedimento armazenado. Procedimento ArmazenadoUm procedimento armazenado é um procedimento independente que geralmente reside no servidor de banco de dados. Os procedimentos armazenados são documentados como operações agrupadas em classes estereotipadas como <<Contêiner de SP>>. As operações são estereotipadas como <<SP>>. O exemplo a seguir mostra uma única operação de procedimento armazenado (SP_Auction) em uma classe de contêiner denominada AuctionManagement. Ao projetar procedimentos armazenados, o designer de banco de dados deve estar ciente de quaisquer convenções de nomenclatura utilizadas pelo RDBMS específico.
Exemplo de Contêiner de Procedimentos Armazenados e de Procedimento Armazenado Espaço de TabelasUm espaço de tabelas representa a quantidade de espaço de armazenamento a ser alocado para itens como tabelas, procedimentos armazenados e índices. Os espaços de tabelas estão vinculados a um banco de dados específico por meio de um relacionamento de dependência. O número de espaços de tabelas e como as tabelas individuais serão mapeadas para eles dependem da complexidade do Modelo de Dados. Pode ser necessário particionar as tabelas que serão acessadas com freqüência em vários espaços de tabelas. As tabelas que não contêm grandes quantidades de dados freqüentemente acessados podem ser agrupadas em um único espaço de tabelas. Um contêiner de espaços de tabelas é definido para cada espaço de tabelas. O contêiner de espaços de tabelas é o dispositivo de armazenamento físico para o espaço de tabelas. Embora vários contêineres de espaços de tabelas possam existir para um único espaço de tabelas, recomenda-se que um contêiner de espaços de tabelas seja designado a apenas um único espaço de tabelas. Os contêineres de espaços de tabelas são definidos como atributos para o espaço de tabelas; eles não são modelados explicitamente.
Exemplo de Espaço de Tabelas
Esquema
|









© Copyright IBM Corp. 1987, 2006. Todos os Direitos Reservados. |